Why Your Data Pipeline Works in Dev but Fails in Production?
The gap is rarely the pipeline itself
Shen Pandi
March 23, 2026
A pipeline that runs perfectly in development does not guarantee the same behavior in production. In controlled environments, datasets are smaller, schemas are stable, and dependencies are predictable.
So, you are working with sampled data, fixed credentials, and isolated services that rarely reflect the variability of real traffic.
Production introduces an entirely different reality as data arrives in high volume, often from multiple upstream systems that evolve independently.
In this scenario schema variations, late-arriving records, inconsistent timestamps, and partial failures begin to surface. Transformations that seemed deterministic in dev now interact with noisy inputs, race conditions, and version mismatches across services.
What makes this particularly challenging is that pipelines rarely fail outright. They continue to execute, but the outputs begin to drift.
Also, aggregations no longer align with source systems, joins introduce duplication or loss, and downstream dashboards start reflecting subtle inconsistencies.
From the outside, everything appears operational, yet the reliability of the data quietly degrades under production conditions.
When Development Logic Breaks Under Real-World Traffic
Airbnb has faced challenges where data pipelines that worked correctly in development began producing inconsistent results in production due to differences in data volume, schema evolution, and event timing.
In controlled environments, joins across datasets like bookings, listings, and user activity behaved as expected because the data was clean and relatively uniform. Once deployed, the same pipelines had to process high-velocity event streams with missing fields, delayed updates, and inconsistent identifiers across services.
This led to subtle issues such as join mismatches, duplicated records, and incomplete aggregations, which in turn caused discrepancies across dashboards and reporting layers.
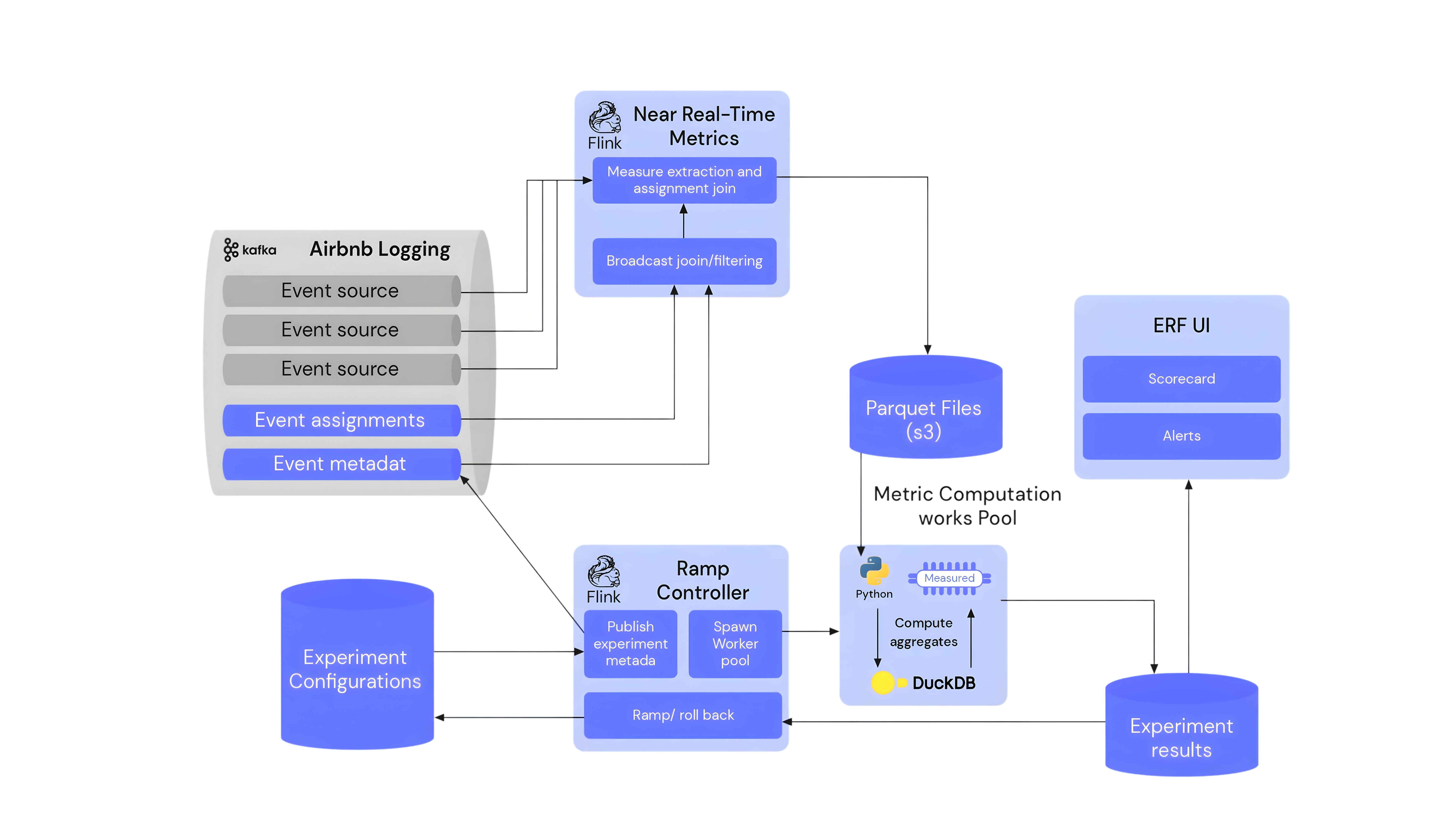
While the pipelines did not fail “technically,” the outputs began to drift from expected values, especially in metrics that depended on multiple data sources.
To address this, Airbnb strengthened its data governance by introducing stricter schema validation, improving data quality checks across pipelines, and enforcing clearer contracts between upstream producers and downstream consumers.
This helped ensure that production data adhered more closely to expected structures and reduced inconsistencies caused by evolving inputs.
How DataManagement.AI Bridges the Dev–Prod Divide
This is where DataManagement.AI helps eliminate the disconnect between development assumptions and production reality.
Its Data Quality Monitoring continuously evaluates incoming data across schemas, validating field types, enforcing business rules, and tracking anomalies as they occur in real time.
Instead of relying on post-deployment observation, pipelines are monitored against defined expectations such as null thresholds, range constraints, and referential integrity, ensuring that deviations are identified immediately.
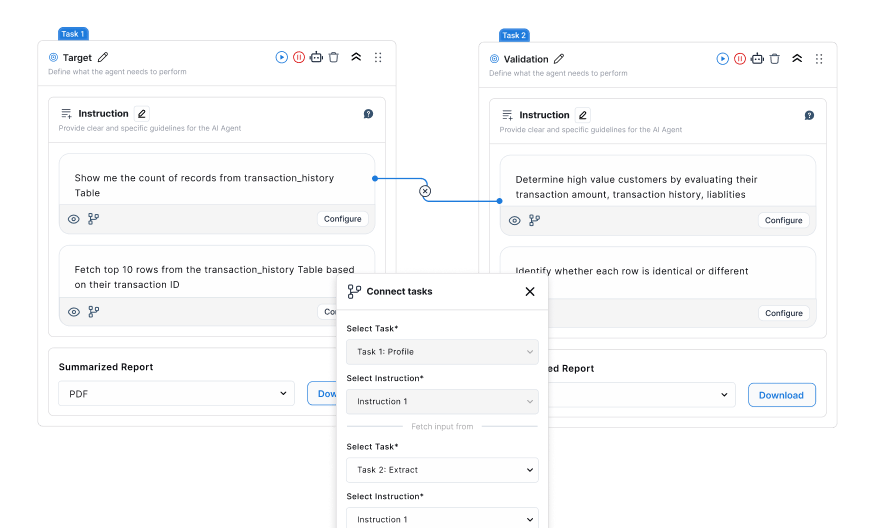
At the same time, its Master Data Management capability ensures that entities like customers, products, and transactions remain consistent across systems.
By extracting records from multiple sources, matching identifiers such as emails, SKUs, or tax IDs, and consolidating them into a single golden record, it removes ambiguity caused by duplicated or conflicting entries.
Enrichment from external reference sources and maintained change logs further ensure that all systems operate on a unified and continuously updated dataset.
Together, these capabilities align development and production environments by enforcing the same validation rules, entity definitions, and data standards across the entire lifecycle of the pipeline.
This reduces drift, improves consistency, and ensures that what works in testing behaves predictably once exposed to real-world data conditions.

Lastly, The One Gap That Quietly Breaks Production Pipelines
Most teams focus heavily on building and testing the pipeline logic itself, but overlook a critical gap that only appears in production: the absence of enforced data contracts across systems.
In development, assumptions about schema, formats, and dependencies are often implicit and shared informally between teams. In production, however, upstream systems evolve independently, and without explicit contracts, even minor changes can propagate unnoticed.
This gap becomes more visible when multiple producers and consumers interact with the same datasets.
Without strict validation, versioning, and monitoring of schema changes, pipelines remain technically correct but contextually misaligned. The result is not failure in execution, but failure in interpretation.
Closing this gap requires treating data as a governed interface rather than a passive byproduct. When schema definitions, validation rules, and entity identities are consistently enforced across environments, the difference between development and production begins to disappear.
Warm regards,
Shen and Team