Why Semantic Layers Are Replacing Simple RAG?
Integrating Semantic Layers for Smarter Agents.
Shen Pandi
October 22, 2025
You have likely implemented Retrieval-Augmented Generation (RAG) to ground your large language models in enterprise data. However, if your approach still centers on simple vector search and text chunk retrieval, your systems are becoming obsolete.
RAG is undergoing a fundamental transformation into a broader, more dynamic discipline: context engineering.
For you, this signifies a strategic shift from passively feeding data to LLMs to architecting intelligent environments where AI agents can actively manage, manipulate, and reason with context throughout complex workflows.
What You've Learned About RAG's Limitations in Practice
Your experience scaling beyond initial proofs-of-concept has undoubtedly revealed critical flaws in naive RAG implementations.
When you moved from demo environments to production systems, you encountered several fundamental challenges that basic RAG cannot adequately address.
You have likely grappled with context poisoning, where irrelevant or contradictory information infiltrates the context window, leading to inaccurate or nonsensical model outputs.
This occurs when your retrieval system pulls in data that seems semantically similar but is contextually inappropriate, corrupting the entire reasoning process. The more data sources you integrate, the more prevalent this problem becomes.

You've also faced performance degradation, where the sheer volume of retrieved data overwhelms the model's reasoning capacity.
Recent research from Chroma and others has identified this as "context rot" or "context distraction," where model accuracy actually decreases beyond a certain context size.
Your teams have probably noticed that throwing more data at the problem doesn't always yield better results and often makes them worse.
Most significantly, you've encountered substantial enterprise constraints that simple RAG demos conveniently ignore.
These include data security requirements, lineage tracking needs, governance mandates, and quality assurance processes that are non-negotiable in your production environment.
As your retrieval systems scale, these constraints become increasingly complex to manage.
As Douwe Kiela, a co-author of the original RAG paper, confirms, your experience:
People think that RAG is easy because you can build a nice RAG demo on a single document very quickly now. But getting this to actually work at scale on real-world data where you have enterprise constraints is a very different problem.
The scaling challenge is particularly acute. Chief Evangelist at Contextual AI, Rajiv Shah, notes,
I think the trouble that people get into with it is scaling it up. It's great on 100 documents, but now all of a sudden I have to go to 100,000 or 1,000,000 documents.
This exponential increase in data volume fundamentally changes the retrieval dynamics and requires entirely new approaches.
How You Should Now Conceptualize Context Engineering?
Context engineering represents the necessary evolution for your AI infrastructure. Think of it as "the art and science of filling the context window with just the right information at each step of an agent's trajectory," as Lance Martin of LangChain defines it.
This represents a fundamental shift from static retrieval to dynamic context management.
What is context engineering❓
And why is everyone talking about it...👇
Context engineering is rapidly becoming a crucial skill for AI engineers. It's no longer just about clever prompting; it's about the systematic orchestration of context.
🔷 The Problem:
Most AI agents
— Akshay 🚀 (@akshay_pachaar)
12:55 PM • Jul 26, 2025
Your systems must now be capable of a more sophisticated set of actions beyond mere retrieval. You need to implement capabilities for agents to write or persist information between tasks, creating a form of persistent memory that enables continuous learning and adaptation across workflows.
This memory function allows your agents to maintain context across extended conversations and multi-step processes.
You also need compression mechanisms that can condense extensive context through techniques like summarization or 'pruning' to maintain focus and relevance.
As agents accumulate information across multiple tasks, they need ways to distill the most crucial elements without losing essential meaning.
This compression is vital for managing the limited context window effectively.
The ability to isolate and distribute information across specialized agents is another critical capability.
This allows different agents to explore various aspects of a problem simultaneously, much like how Anthropic describes enabling agents to "explore different parts of the problem simultaneously."

By isolating context, you prevent information overload and enable more focused, specialized reasoning.
Most importantly, your systems must excel at selecting the most appropriate data, tools, and memories dynamically for each specific task.
This involves sophisticated routing and decision-making about what information is relevant at any given point in the agent's workflow.
This dynamic orchestration of context is precisely what DataManagement.AI delivers through our "Context Cloud" architecture.
We provide the intelligent data fabric that automatically routes, isolates, and serves the most relevant data to your AI agents in real-time.
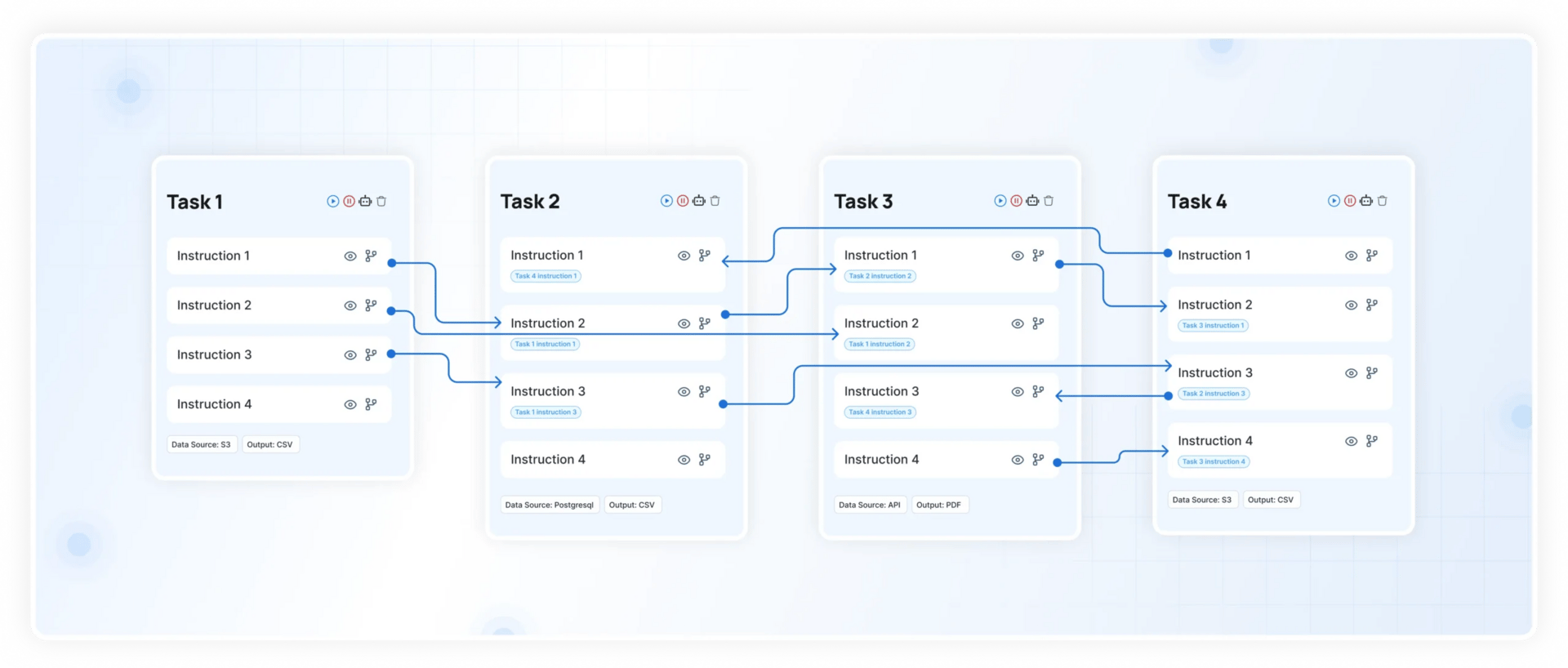
Our platform ensures that every decision point in your agent's workflow is powered by clean, governed, and contextually-perfect information, eliminating noise while maximizing reasoning accuracy.
In this new paradigm, vector-based retrieval becomes just one tool among many in your agent's arsenal.
As Mark Brooker from AWS insightfully notes,
I do expect what we're going to see is some of the flashy newness around vector kind of settle down and us go to a world where we have this new tool in our toolbox, but a lot of the agents we're building are using relational interfaces.
They're using those document interfaces. They're using lookup by primary key and lookup by secondary index.
They're using lookup by geo. All of these things that have existed in the database space for decades, now we also have this one more, which is kinda a lookup by semantic meaning, which is very exciting and new and powerful."
The most advanced implementations already reflect this multi-modal approach.
Varun Mohan of Windsurf describes their approach:
We rely on a combination of techniques like grep/file search, knowledge graph based retrieval, and … a re-ranking step where [context] is ranked in order of relevance.
This represents the sophisticated, hybrid approach you should be building toward.
What You Need to Build Next: A Unified Semantic Layer
To operationalize context engineering across your entire data estate, you must invest in a robust semantic layer. This layer acts as a universal translator, providing consistent, machine-readable meaning to all your assets.
It's the foundation that enables your agents to understand not just what data exists, but what it means and how it interrelates.
Your semantic layer cannot be limited to relational data; it must be a comprehensive metadata framework that interconnects all your information assets.
This includes your structured data in relational databases and data warehouses, which provide the transactional backbone of your organization.
It also encompasses your unstructured and semi-structured content in documents, emails, and media files, which often contain crucial contextual information.

Beyond traditional data sources, your semantic layer must also integrate your available AI tools, agent capabilities, and operational memories. This ensures that your agents can discover and leverage the full range of resources available to them.
Most critically, it must encode your governance policies, data access controls, and compliance requirements to ensure that all interactions remain within appropriate boundaries.
Knowledge graphs are emerging as the critical technology for implementing this comprehensive semantic layer. They excel at modeling the complex relationships and entities that give context its true meaning and explainability.
The recent market consolidation around knowledge graph technologies, including Samsung's acquisition of Oxford Semantic Technologies, the formation of Graphwise through the merger of Ontotext and Semantic Web Company, and ServiceNow's acquisition of data.world, signals the growing recognition of their importance.
As Gartner recommended in their May 2025 report "Pivot Your Data Engineering Discipline to Efficiently Support AI Use Cases," data engineering teams should "adopt semantic techniques (such as ontologies and knowledge graphs) to support AI use cases."
This endorsement underscores the strategic importance of these technologies for enterprise AI initiatives.
If you're looking to navigate these exact challenges, don't miss the upcoming session, "Solving Data Challenges in the Age of AI."

Join Shen Pandi, Founder of Towards AGI, as he delves into the pivotal issues of data quality, governance, and scale that can make or break your AI strategy.
Only a few spots left. Hurry up!
The semantic layer you build must bridge the gap between the rigorous world of relational data management and the contextual richness of library sciences and knowledge graphs.
It should draw inspiration from decades of work in information retrieval, knowledge organization, and Semantic Web technologies while meeting the scalability and performance requirements of modern enterprise systems.
This is the exact challenge that DataManagement.AI is designed to solve. Our platform provides a production-ready semantic layer that unifies your structured and unstructured data estates, transforming them into a coherent, AI-ready knowledge fabric.

By embedding decades of data management best practices with modern AI-native architecture, DataManagement.AI ensures your context engineering initiatives are built on a foundation of governed, discoverable, and interoperable data, dramatically accelerating your path to reliable agentic AI.
How You Should Evaluate Your Evolving System's Performance
As you progress beyond basic RAG, your evaluation metrics must become more sophisticated and comprehensive.
You need to look beyond simple answer accuracy and implement a multi-dimensional measurement framework that captures the full quality of your context engineering system.
You should be measuring context relevance to ensure the retrieved information is actually pertinent to the query and the agent's current goal.
This goes beyond semantic similarity to assess whether the context actually helps solve the specific problem at hand.
Tools like Ragas, Databricks Mosaic AI Agent Evaluation, and TruLens provide frameworks for this type of assessment.

Groundedness is another critical metric, ensuring that the final response is well-supported by the provided context and source data. This helps prevent hallucination and ensures that your agents' outputs are reliable and trustworthy.
You need to verify that claims made by your agents can be traced back to specific, credible sources within your knowledge base.
Provenance tracking is essential for auditability and trust. You must be able to perfectly trace every claim back to its original source, understanding not just where information came from but how it was processed and transformed through your system.
This becomes particularly important in regulated industries or when making significant business decisions based on AI outputs.
Coverage assessment ensures that your retrieval mechanisms capture a sufficient breadth of necessary information. This involves evaluating whether your system is missing critical context that would lead to better outcomes.
It's about ensuring completeness rather than just precision in information retrieval.
Recency evaluation guarantees that the context is sourced from data that is current and up-to-date. For many business applications, stale information can be as damaging as incorrect information.
You need mechanisms to prioritize and validate the timeliness of your data sources.
Additionally, you should be implementing policy compliance metrics to ensure that all retrieval and usage respects access controls and governance requirements.
As Dr. Sebastian Gehrmann of Bloomberg warns,
RAG is not necessarily safer," and can introduce new governance risks if not properly constrained.
The future of intelligent data retrieval in your organization will be characterized by several key developments that you should be preparing for now.
First, you need to design for agentic patterns where retrieval is embedded within iterative reasoning loops rather than executed as a one-off step.
This means building systems that can dynamically adjust their information needs based on intermediate results and evolving understanding.
Frameworks like LangChain's LangGraph and approaches like Anthropic's Model Context Protocol (MCP) are pioneering this direction, treating retrieval as a tool that agents can call iteratively throughout their workflow.
However, these powerful frameworks require a robust data foundation to be truly effective.
This is where DataManagement.AI delivers critical value; we provide the unified data fabric that ensures every agentic retrieval, whether through LangGraph, MCP, or other frameworks, accesses clean, governed, and contextually relevant data.

Our platform transforms your disparate data sources into a coherent knowledge base that intelligent agents can reliably query and reason over throughout their entire workflow lifecycle.
Second, you must plan for multimodal retrieval capabilities that span all your data types. Your systems will need to seamlessly retrieve from diverse sources, relational databases, document stores, knowledge graphs, image repositories, and audio/video content.
LlamaIndex's four 'retrieval modes' (chunks, files_via_metadata, files_via_content, auto_routed) and Snowflake's Cortex Search (for content) and Cortex Analyst (for relational data) represent early steps in this direction.
Third, you need to implement policy-aware systems where governance is baked directly into the retrieval process. This involves using policy engines like Open Policy Agent (OPA) and Oso to embed complex access control and compliance logic into your agentic workflows.
As your systems become more autonomous, these guardrails become increasingly critical for safe operation.
Fourth, you should prioritize explainable outcomes powered by knowledge graphs and rich semantic relationships. The ability to understand not just what answer was generated but why it was selected and how it was derived is essential for building trust and facilitating human oversight.
The market trends clearly indicate this direction. The acquisitions and mergers in the knowledge graph space, coupled with initiatives like Snowflake's Open Semantic Interchange (OSI), demonstrate the industry's recognition that semantic understanding is fundamental to next-generation AI systems.

As you build out these capabilities, remember that this is not a one-time project but an ongoing evolution.
You need to establish continuous evaluation processes, regularly update your semantic models, and adapt your governance frameworks as new challenges and opportunities emerge.
RAG was merely the starting point on your journey toward creating AI systems that genuinely comprehend and reason with your enterprise's knowledge.
By embracing context engineering and constructing the semantic infrastructure to support it, you will empower AI agents that do not just find data but truly understand your business context, navigate intricate processes, and make informed decisions, all within the secure and governed boundaries your enterprise requires.
The organizations that master this transition will not just have more efficient AI systems; they will have created a fundamental capability for intelligent, adaptive operation that can drive competitive advantage for years to come.
Your investment in context engineering today will determine your organization's AI maturity and capability tomorrow.
Warm regards,
Shen and Team