Why Do Data Migration Projects Take 3× Longer Than Planned?
it’s everything you didn’t model
Shen Pandi
April 14, 2026
If you have led a data migration, you know the process appears deterministic: extract, transform, load, and validate, with defined timelines and dependencies. In practice, delays occur when edge cases, inconsistencies, and reconciliation mismatches surface during execution.
The underlying issue is that migration involves more than data movement. It requires reconstructing implicit assumptions embedded in evolving schemas, layered transformations, and undocumented business logic.
Legacy systems encode semantics that only become visible when data is reinterpreted in a new environment.
Where do migrations actually break?
Most migration delays do not stem from infrastructure or tooling limitations; they arise from data inconsistencies that only surface during reconciliation.
After migration, validation checks such as row counts, schema alignment, and pipeline execution often pass, creating a false sense of correctness.
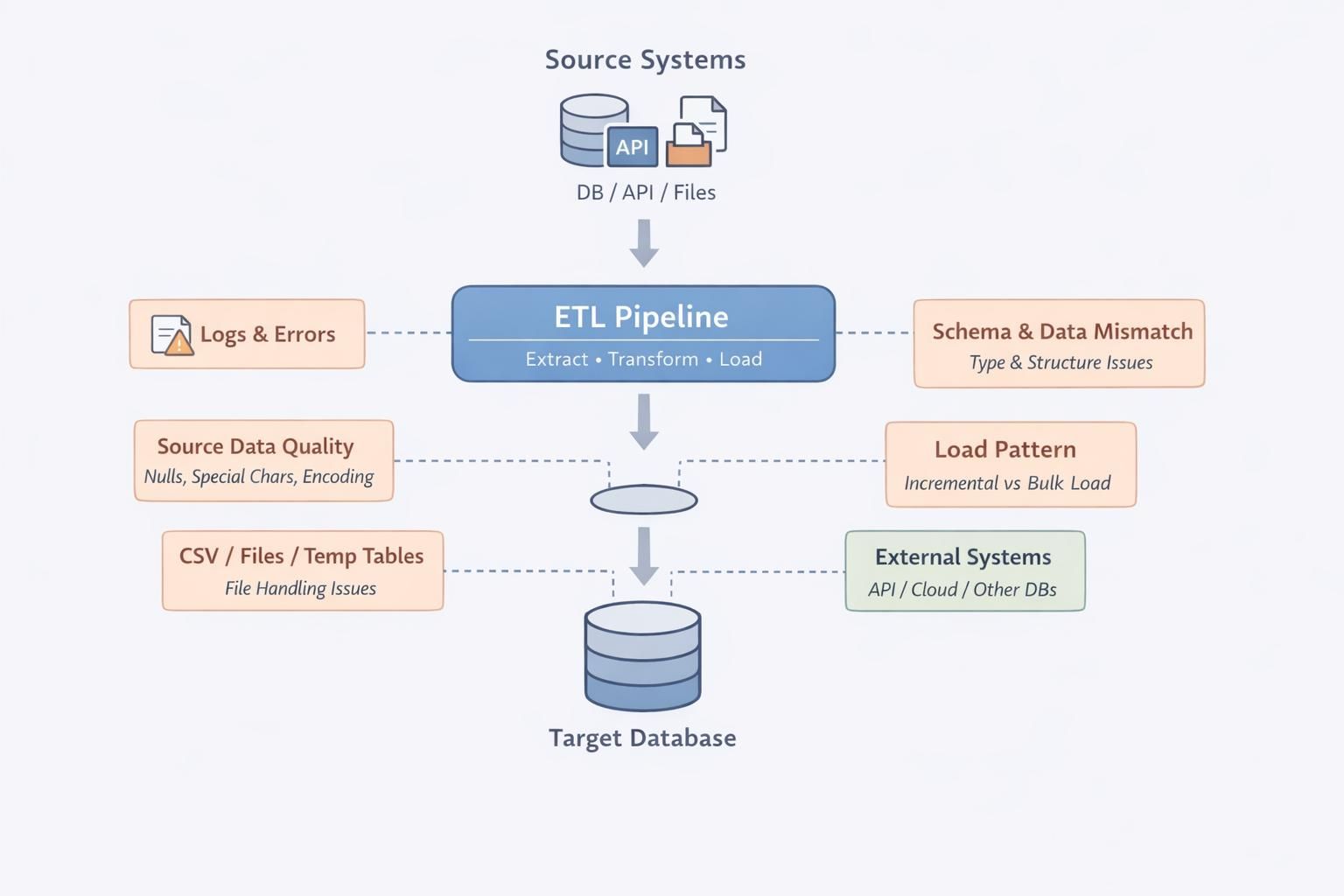
Discrepancies emerge when financial or analytical systems compare outputs, revealing mismatched totals, inconsistent historical behavior, and shifted derived metrics. These issues occur because legacy transformations embed business logic across ETL pipelines, application layers, and reporting queries.
When rebuilding in the target system, teams reconstruct this logic with incomplete context, resulting in technically valid but semantically inconsistent data.
Why do issues surface so late?
One of the biggest reasons migrations overrun timelines is that issues are detected too late in the process.
Most teams rely on batch validation and periodic testing. Data is migrated, checks are run, and only then are discrepancies identified. By that point, the issue has already propagated through multiple datasets and transformations.
Fixing it requires tracing the problem back through layers of pipelines, reprocessing data, and rerunning validations. Each cycle adds more time.
What is missing is real-time visibility into how data behaves during migration, not after it completes.
This is where DataManagement.AI change the equation. Instead of waiting for batch validation, its Real-Time Alerts & Notifications continuously monitor streaming and near-real-time metrics during migration.
If a threshold is breached, such as unexpected drops in record counts, spikes in null values, or deviations in key metrics, alerts are triggered immediately and routed to the right stakeholders based on predefined escalation paths.
This reduces detection time from hours or days to minutes, allowing teams to intervene before issues cascade across the pipeline.
When issues are detected late, the cost is not just technical. It affects the entire organization.
Teams are pulled into extended debugging cycles. Business stakeholders lose confidence in the migration. Decision-making slows down because data cannot be trusted.
More importantly, every delay compounds. Fixing one issue often reveals another, because the underlying problem is not isolated. It is systemic.
Real-time alerting introduces accountability into the process. Alerts are not just notifications, they carry context, ownership, and resolution tracking. Teams know what broke, where it broke, and who needs to act.

What should you do differently?
If you want your next migration to stay on track, you need to rethink how you approach validation and monitoring.
Do not treat migration as a one-time event followed by validation. Treat it as a continuous process where data is observed, validated, and corrected in real time.
This means instrumenting pipelines with live metrics, defining alert rules for critical thresholds, and ensuring that every anomaly is surfaced immediately with clear ownership.
Because migrations do not fail because data cannot be moved. They fail because issues are discovered too late to fix efficiently.
And by the time you see the problem, the timeline has already slipped.
Warm regards,
Shen Pandi & Team