The Silent Failures Your Data Stack Won’t Tell You About
Why everything looks fine until decisions go wrong
Shen Pandi
March 24, 2026
Silent data failures occur when pipelines execute successfully, but the outputs are incorrect, incomplete, or misleading. Unlike traditional failures, there are no crashes, exceptions, or alerts.
The system continues to run, dashboards refresh, and metrics appear consistent, which creates the illusion of correctness.
In modern data stacks, this issue emerges due to a combination of factors including schema drift, inconsistent upstream transformations, late-arriving data, and subtle mismatches in joins or aggregations.
Each component in the pipeline may function as designed, yet the interaction between them introduces distortions that are not immediately visible.
The risk lies in the absence of explicit signals. Since no errors are triggered, teams often rely on surface-level indicators such as pipeline completion status or dashboard availability.
However, these signals do not validate the correctness of the data itself. That’s why, incorrect data flows downstream into analytics, forecasting models, and operational systems, where it influences decisions without detection.
How Uber Encountered Silent Data Issues in Its Marketplace Systems
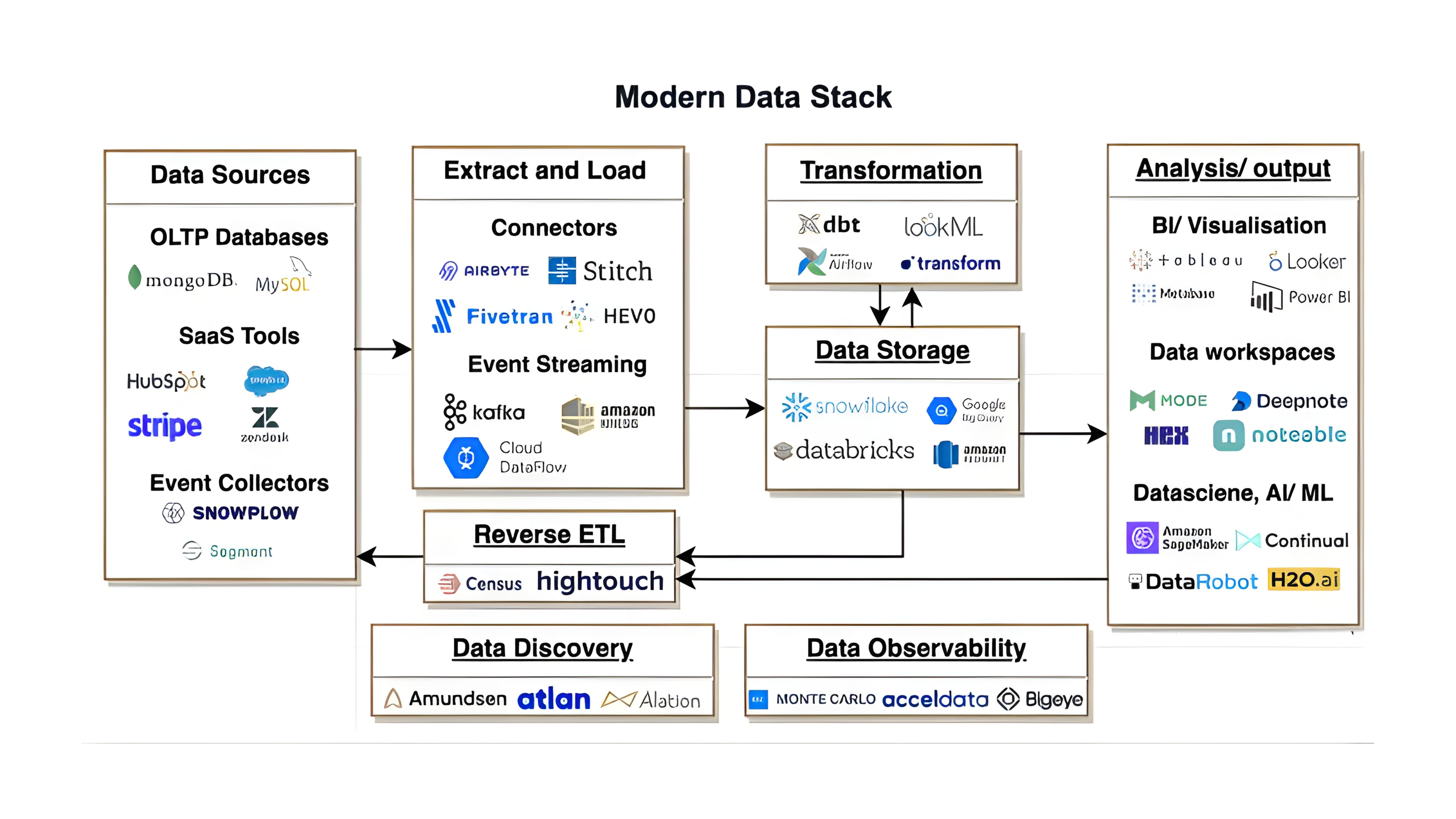
Uber’s data ecosystem provides a clear example of how silent failures can emerge at scale. It relies on real-time and batch pipelines to process data across riders, drivers, trips, pricing, and demand forecasting. These pipelines operate on distributed systems with multiple upstream producers emitting event streams at high velocity.
In production, Uber has had to manage challenges related to late-arriving events, schema evolution, and inconsistent data across services.
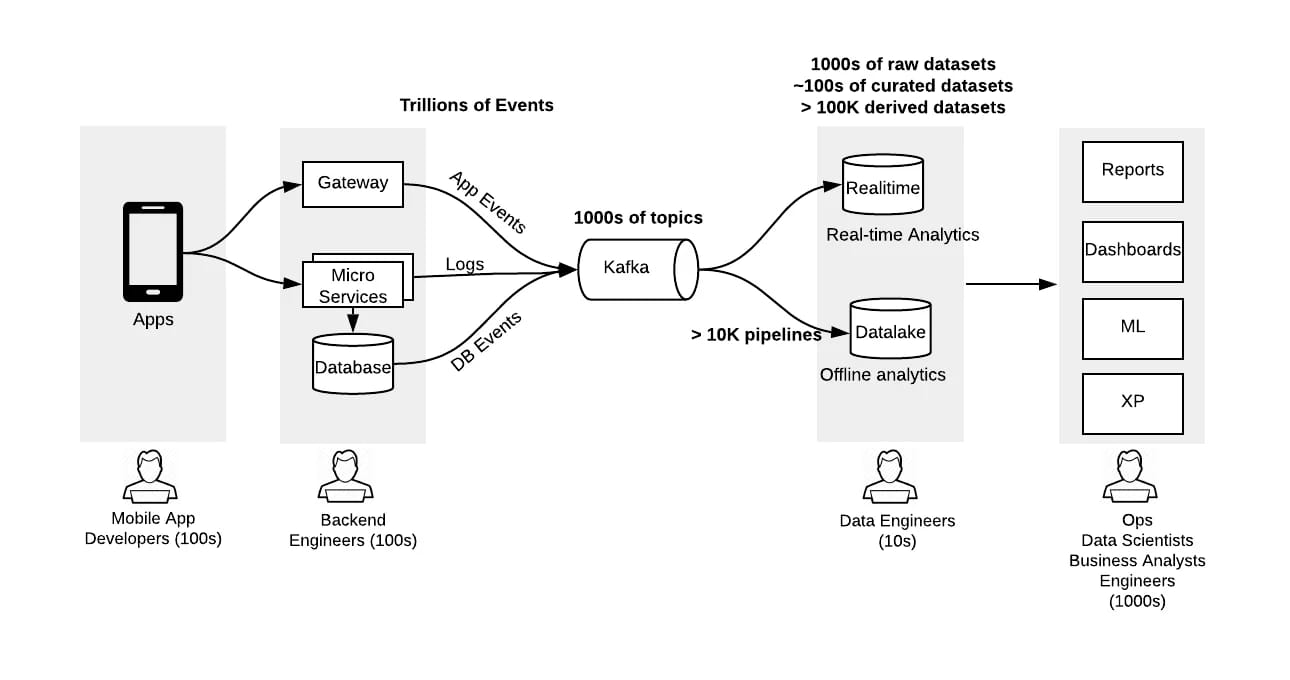
Uber’s data framework
For example, trip events generated from different services may arrive out of order or with slight variations in structure.
A simple but common issue arises when a trip is updated after completion, such as a correction in fare due to a toll or route adjustment. If the updated event arrives later than the original event, some pipelines may have already aggregated the earlier value.
Therefore, payment, trip duration, or revenue metrics can temporarily reflect outdated or mismatched values.
While pipelines continue to execute successfully, joins across datasets such as trips, payments, and user activity can produce incomplete or skewed aggregations if records are missing, duplicated, or misaligned.
Uber addressed these challenges by investing heavily in data validation frameworks, schema enforcement, and monitoring systems that track data quality across pipelines.
By introducing stricter contracts between services and improving observability into data flows, the platform reduced the impact of silent inconsistencies and improved the reliability of downstream analytics used for pricing, operations, and marketplace balancing.
How DataManagement.AI Detects and Prevents Silent Failures
DataManagement.AI’s ‘Operational Anomaly Detection’ continuously monitors key performance metrics like transaction volumes, error rates, and response times by analyzing real-time time-series data against historical baselines.
It establishes normal behavior using statistical patterns like mean and standard deviation, and then identifies deviations as they occur.
The system also incorporates contextual signals like system load, user activity, and recent incident logs to improve accuracy and reduce false positives.
Maintenance events and recent pipeline changes are also factored in to distinguish expected fluctuations from genuine anomalies. This allows the platform to correlate spikes or drops in metrics with underlying operational conditions rather than treating them in isolation.
The result is a real-time alert feed that ranks anomalies by severity and provides contextual insights for faster investigation. Instead of discovering issues during periodic reviews or after business impact has occurred, teams are notified as deviations begin to emerge.
This improves detection speed, reduces reliance on manual monitoring, and ensures that silent anomalies affecting data pipelines, infrastructure, or downstream metrics are identified before they propagate further.

What Most Teams Miss When Trying to Solve This Problem
Most organizations attempt to address silent failures by focusing on pipeline reliability, monitoring job execution, or improving infrastructure stability.
While these are important, they do not fully address the underlying issue. The gap lies in the lack of validation of data correctness itself once the pipeline completes.
Pipelines can succeed operationally while still producing incorrect outputs if upstream data changes, schemas evolve, or assumptions embedded in transformations no longer hold.
Without continuous checks on data quality, schema consistency, and entity alignment, these issues remain invisible until they surface in reconciliations or financial reporting.
Closing this gap requires shifting focus from pipeline success to data correctness. When validation is applied at the data level, across schemas, entities, and transformations, silent issues become detectable early.
This ensures that what reaches downstream systems is not just processed data, but verified and consistent information that can be trusted for decision-making.
Warm regards,
Shen and Team