The Only 3 Data Quality Checks That Actually Matter
everything else is just noise
Shen Pandi
April 06, 2026
Most data teams assume their data quality framework is sufficient because standard checks like null validations, row counts, and schema enforcement pass consistently. Pipelines run without errors, dashboards refresh on time, and everything appears reliable.
Yet issues still surface at the business layer. Financial reports diverge, product metrics stop aligning, and engineering teams end up debugging pipelines that technically never failed.
The problem is that most checks are built to catch structural issues, not semantic or statistical ones. They can detect missing or malformed data, but they miss distribution shifts, join inconsistencies, and changes in how metrics are computed.
If you want real data reliability, the focus needs to shift to a smaller set of high-signal validations that track how data behaves over time. These are the checks that expose real production issues, and they are the ones most teams still do not automate.
Distribution Drift Detection (Not Just Volume Checks)
Row count and null checks are useful for identifying missing data, but they do not validate whether the data itself is correct or representative of expected behavior. A dataset can pass all basic validation checks and still contain significant inaccuracies that impact downstream systems.
In practice, most production failures are caused by shifts in data distribution rather than outright data loss.
For example, a pricing column that historically followed a stable range may begin to skew due to upstream logic changes or data ingestion issues.
Similarly, a categorical feature may start exhibiting a different value distribution, with certain categories becoming disproportionately dominant. In machine learning pipelines, even small shifts in feature distributions can lead to degraded model performance without triggering standard alerts.
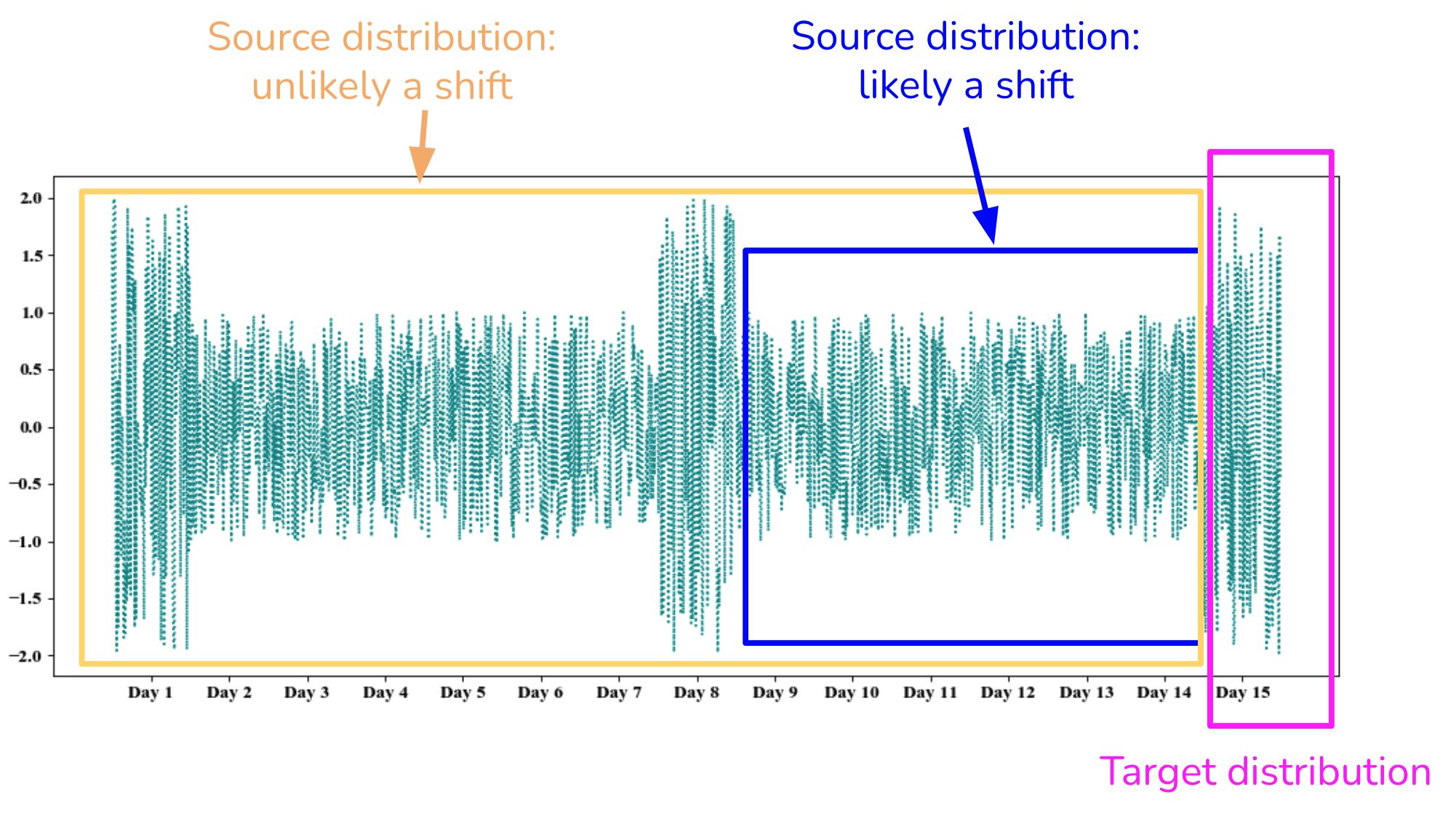
These issues do not manifest as system failures; they appear as subtle deviations in data behavior that accumulate over time. Because pipelines continue to execute successfully, these changes often go undetected until they impact business outcomes.
Automating distribution drift detection requires continuously comparing incoming data against historical baselines at multiple levels of granularity. This includes monitoring statistical properties such as percentiles, variance, and frequency distributions at both column and segment levels.
By establishing thresholds for acceptable deviation, teams can detect when data begins to diverge from expected patterns.
Without these checks, a pipeline can remain fully operational from an execution standpoint while producing outputs that are statistically inconsistent and misleading.
Join Integrity Validation (The Most Ignored Failure Mode)
Most data pipelines rely heavily on joins to combine datasets, yet very few teams implement systematic validation around how those joins behave in production.
Every join is built on an implicit assumption about cardinality, whether it is one-to-one, one-to-many, or many-to-one. When that assumption changes due to upstream data variations, the pipeline does not necessarily fail. Instead, it continues executing while producing structurally valid but logically incorrect outputs.
For example, a join that was originally one-to-one can evolve into a one-to-many relationship if duplicate keys are introduced upstream, leading to inflated row counts and overestimated aggregates.
Similarly, missing or null keys can result in silent row drops, while late-arriving or asynchronous datasets can create partial joins that distort time-based aggregations and reporting accuracy.
These issues are not captured by conventional data quality checks such as schema validation or row-level completeness. Queries execute successfully, tables are populated without errors, and dashboards appear consistent, even though the underlying data relationships have changed.
Automating join integrity requires explicitly validating expected cardinality constraints, continuously monitoring duplication and fan-out rates, and enforcing referential completeness between joined datasets. It also involves tracking how join outputs evolve over time and triggering alerts when deviations from expected patterns occur.
Without these controls, aggregation logic operates on assumptions that are neither validated nor enforced, making the resulting metrics inherently unreliable.
Semantic Consistency Checks (Not Just Schema Validation)
Schema validation ensures that data conforms to expected structures, such as field presence, data types, and formats, but it does not validate whether the data is logically or contextually correct. A dataset can pass all schema checks and still produce incorrect business outcomes if the underlying relationships and assumptions are violated.
Most high-impact failures occur at the semantic layer, where metrics are expected to align with business logic. For instance, revenue reported across billing and finance systems may not reconcile due to inconsistencies in fee calculations or currency conversions. Conversion rates may exceed logical bounds because of duplicated events or incorrect denominators. Aggregated metrics that should mathematically align across dimensions often diverge due to subtle issues in upstream transformations.
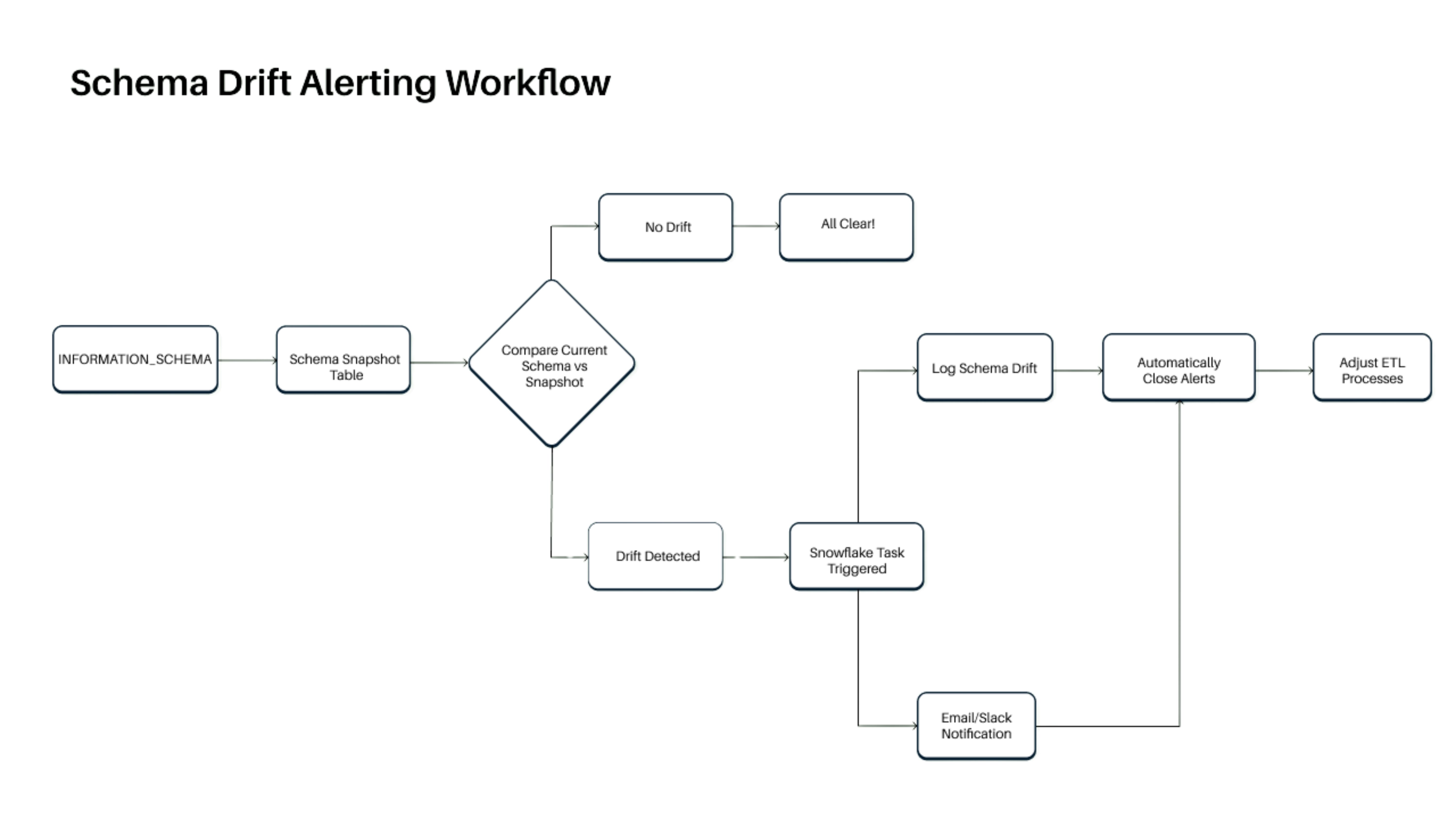
These are not failures at the infrastructure or schema level. They are violations of defined business rules that were never explicitly enforced within the data pipeline.
Automating semantic validation requires encoding these business rules directly into the data processing layer. This includes enforcing constraints such as net revenue equaling gross revenue minus commissions and refunds, validating referential consistency across aggregated dimensions, and ensuring derived metrics remain within defined thresholds. These checks must operate continuously on production data, not just during initial pipeline setup.
In practice, this is where DataManagement.AI integrate into the workflow by operationalizing these validations. Instead of relying on static checks, the platform continuously evaluates data against business rules, monitors deviations in real time, and correlates them with upstream changes in data or transformations.

Combined with anomaly detection, this approach ensures that both structural correctness and semantic integrity are maintained, allowing teams to identify logical inconsistencies before they propagate into reporting, forecasting, or decision-making systems.
What Is Your Team Still Getting Wrong?
The mistake most teams make is assuming that more checks equal better data quality. In reality, most checks are redundant and focus on surface-level validation.
What actually matters is whether your checks are aligned with how data breaks in production. Data does not usually fail loudly. It shifts, drifts, and misaligns.
If your validation strategy is not designed to detect those patterns, you are not really monitoring data quality. You are monitoring pipeline execution.
And those are two very different things.
Warm regards,
Shen Pandi & Team