The Architectural Shift in Enterprise Data Ecosystems
From Pipelines to Agents.
Shen Pandi
February 26, 2026
AI Agents Defined: Autonomous systems that perceive and adapt in real time.
Agentic Data Management (ADM): Using AI agents to automate the entire data lifecycle.
Core Function: Interprets intent, executes plans, and adapts dynamically without manual coding.
Why It Matters: Fixes the scalability issues of manual data management.
Key Capability: Understands the meaning of data (semantics), not just its structure.
The Outcome: Data teams shift from manual builders to strategic supervisors.
You might not see them, but they are there. AI agents are increasingly embedded in the systems you use every day, autonomously performing tasks that used to require your direct oversight.
Think about an autonomous vehicle. It senses its surroundings, evaluates context, and makes split-second decisions in real time. It navigates not because a human programmed every possible scenario, but because it continuously interprets signals and adapts as the environment changes.
Now, imagine bringing that same level of intelligence to your data program.
You have thousands of datasets. Millions of records. Billions of data-driven decisions are being made across your organization. Managing that manually is no longer feasible.
This is where agentic data management (ADM) comes into play. By leveraging the decision-making capabilities of AI-powered agents, you can begin to reinvent how you process, govern, and actually use your data.
With DataManagement.AI, you move from static data management tools to a dynamic, intelligent system where agents continuously monitor, clean, and prepare your data.

They learn from usage patterns, adapt to new data sources, and ensure your data is always trustworthy and actionable, exactly what agentic data management promises.
What Agentic Data Management Means for You
Agentic data management is the application of AI agents to coordinate and optimize your entire enterprise data program. Instead of you or your team scripting every move, these agents handle the heavy lifting across:
Building data pipelines
Discovering new data sources
Provisioning and tiering storage
Maintaining semantic consistency across systems
Enforcing governance and access controls
Monitoring data quality and integrity in real time
Optimizing workloads and performance
Producing analytics and business intelligence insights
Rather than relying on rigid, hand-coded workflows, ADM introduces intelligence to each stage of your data lifecycle.
The system interprets intent, determines what data and policies are relevant, and adapts operations automatically as conditions change, without you needing to rewrite a single line of code.

At the core of this capability are large language models (LLMs). They provide the reasoning layer inside these agents, using natural language processing to interpret what you need and translate that into a coordinated data strategy.
Think of it like using ChatGPT or Google Gemini: you state what you want, and the system figures out the rest. It draws on metadata, data lineage, machine learning, and business rules to determine what data is relevant, how it should be validated and governed, and how it should be prepared for downstream analytics.
From there, the agentic system outlines the steps required to complete the task. That might mean accessing sources, enforcing policies, optimizing workloads, managing storage, and ultimately delivering trusted outputs.
Why This Is Different from What You Are Doing Today
What distinguishes agentic data management from the tools you likely use now is that it is self-adaptive. It evolves based on context. It continuously learns from signals and adjusts as conditions change, rather than treating your workflows as fixed artifacts that break the moment something shifts.
Imagine you are a supply chain manager. You might give an instruction like: "Monitor incoming feeds and resolve duplicate records as they appear."

As new orders arrive, the AI-driven system interprets your intent and adapts its plan in real time. It merges records, flags inconsistencies, and delegates tasks to specialized agents, all without you needing to intervene.
While this is still an emerging approach, organizations like yours are already using ADM to improve data reliability and operational efficiency through:
Automated data quality and validation: Catching data drift, inconsistencies, and unexpected changes as data moves across your organization.
Self-service data integration: Turning natural-language requests from your business users into governed, ready-to-use pipelines.
Data alignment: Keeping your CRM, supply chain, and finance systems consistent as definitions or rules change.
Compliance for data in motion: Ensuring data remains compliant as it moves, using continuous observability guardrails to enforce quality, lineage, and regulatory requirements.
Context-aware enrichment: Updating classifications and attributes as your business logic evolves.
Orchestration optimization: Adjusting execution paths based on cost, performance, or system conditions.
Why You Need to Pay Attention to This Now
You are generating more data across more systems than ever before. But as volumes rise and your architecture becomes increasingly hybrid and distributed, you likely struggle to turn that complex data into reliable, real-time insights.
In fact, 76% of businesses admit they have made decisions without consulting data because it was simply too difficult to access.
Your current approach, traditional data management, relies heavily on manual intervention. That makes you slow to adapt when schemas change, metrics evolve, or operational logic shifts.
Agentic data management is gaining momentum because it addresses several systemic pressures that your legacy approaches cannot keep up with:
Rising complexity and fragmented architectures: Your hybrid cloud, multicloud, and distributed data warehouses create dependency chains that are a nightmare to maintain manually. You cannot scale when datasets and APIs evolve daily.
The high cost of low-quality data: Poor data quality is costing you. False KPIs, misaligned forecasts, and outdated customer data impact your downstream systems. The risks compound, especially if you are in a regulated industry like financial services or healthcare.
Demand for real-time decision-making: Your business runs on real-time analytics and AI systems. Those systems require accurate, real-time data. When your pipelines stall or silently fail, latency builds up, decision-making slows down, and your operational efficiency suffers.
Capacity constraints on your data teams: Demand for data is exploding. But your centralized data teams, still dependent on manual integration and delivery, are struggling to keep pace. That bottleneck slows decision-making across your entire organization.
The burden of reactive monitoring: If your data monitoring is largely manual, issues tend to surface only after downstream processes are affected. You end up spending disproportionate time on reactive debugging instead of higher-value work.
You also face structural data challenges that manual approaches simply cannot fix. Over 50% of organizations rely on three or more data integration tools. That creates fragmented workflows and inconsistent logic across your teams.
That fragmentation cascades into broader problems: quality checks happen too late, governance rules drift across systems, lineage breaks go undetected, and semantic definitions fall out of sync.
In reality, 77% of organizations lack the talent to manage this level of complexity.

These pressures directly impact your team. Your engineers spend 10% to 30% of their time just uncovering data issues, and another 10% to 30% resolving them. That is over 770 hours per year per engineer, more than $40,000 in wasted labor.
Meanwhile, your analysts and business users wait an average of one to four weeks for the data they need because integration tasks are siloed or stalled.
Agentic data management represents a fundamental shift in how you ensure data accuracy, quality, and integrity at scale.
Instead of scripting every transformation or maintaining rigid rules, you introduce AI agents to scale pipeline creation, streamline data operations, reduce bottlenecks, and sustain high-quality data with far fewer manual interventions.
With more efficient operations and trusted data across the entire lifecycle, your team can finally focus on strategy rather than rework.
The Core Components You Need to Understand
Agentic data management brings together four core components, each enabled by a coordinated layer of AI models, agents, and semantic technologies. You need to understand how these pieces fit together.
1) Interpreting Intent
When you or a user provides a prompt or request, an agent uses its reasoning capabilities to interpret what is being asked. It devises a plan that outlines the required data assets, governance rules, semantic considerations, validations, and operational steps.
Other agents then assess this plan from their respective domains, confirming the necessary models, business rules, lineage, dependencies, and catalog metadata before any action begins.

For you, this orchestration significantly reduces the need to manually stitch processes together across the data lifecycle. It shortens time-to-data for analytics and aligns data operations with business intent.
Agents can also surface ambiguities and validate assumptions, incorporating your data strategy and governance policies directly into the proposed plan.
2) Executing Plans
Next, AI agents carry out the work defined by the plan. They access and interpret data across your systems, apply governance and quality checks, manage storage behavior, execute data processing steps, and prepare outputs for downstream consumption.
Agents can also optimize for cost or latency, adapt operations when systems fail, and map dependencies across your data ecosystem.
With so many moving parts, AI agents help ensure your data operations remain reliable as schemas evolve or workloads shift. They reduce the repetitive, time-consuming tasks across your data lifecycle and improve scalability for your enterprise data initiatives.
3) Applying Semantic Context
Traditional metadata systems describe structure by capturing fields, formats, and schema definitions.
By contrast, vector databases can operate as a semantic layer, capturing meaning by representing how your data elements relate and the context in which they are used. One outlines the shape; the other reveals its texture.

Vector databases store embeddings that represent your metrics, datasets, and business terms as mathematical vectors. This allows your agentic systems to measure similarity, uncover semantic relationships, and detect shifts in meaning, even when the schema stays the same.
For you, this semantic layer enables context-aware transformations, anomaly detection, semantic drift detection, validation of business rules, and alignment across your data catalog.
4) Enforcing Governance
Effective governance is foundational to agentic data management. Instead of relying on manual reviews, these systems continuously apply policy, quality, and security controls as data moves through its lifecycle.
Validation rules and integrity safeguards are enforced during execution to ensure outputs remain accurate and trustworthy across your enterprise data ecosystem.

You can even deploy lightweight "guardian" agents, small oversight agents that monitor pipeline behavior and health in real time, to maintain observability and surface issues before they compromise downstream workflows.
This added supervision helps keep your automated pipelines fast, reliable, and aligned with your enterprise data management standards.
How This Works in Practice for You
These components come together in a closed-loop workflow that blends your intent, LLM-based planning, AI-orchestrated execution, and continuous validation.

A typical interaction might look like this:
You express intent: You provide a natural-language instruction such as "Combine CRM and supply chain data and detect anomalies."
A plan is made: An LLM-powered planning agent analyzes your instruction, identifies relevant datasets, and produces an execution strategy aligned with your governance policies and data strategy.
The plan is executed: Dedicated agents connect to your systems, pull data from warehouses and APIs, harmonize schemas, apply transformations, validate outputs, and enrich attributes, all in real time.
The system enforces guardrails as it runs: Your data governance policies and semantic checks are enforced automatically at each step. Supervisory logic monitors activity in real time and blocks actions that violate standards.
The workflow adapts to changes: If a schema shifts, a dependency breaks, or a business definition evolves, the system replans the steps and adjusts the orchestration pattern automatically.
Your pipelines will behave rather than execute
Agentic AI moves your workflows beyond static scripts and into adaptive, context-aware behavior. Your pipelines will respond to changes in metadata, business rules, operational load, and governance constraints, altering their execution path instead of breaking when conditions shift.

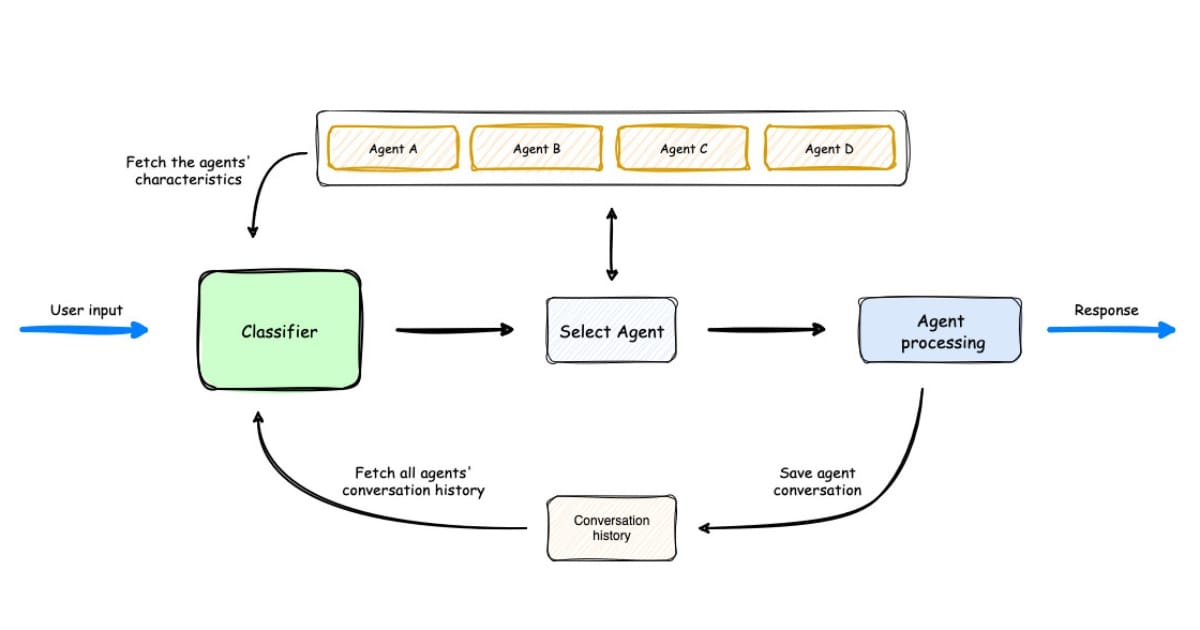
In these agentic architectures, multi-agent systems replace monolithic platforms: specialized agents handle ingestion, quality, lineage, or optimization while a supervisory agent maintains alignment with your intent and policy.
The architecture you just described, specialized agents handling discrete functions like ingestion, quality, lineage, and optimization, all coordinated by a supervisory agent, is precisely how DataManagement.AI is built.

Semantics will matter as much as structure
AI-ready data depends not just on schema accuracy, but on semantic consistency. The data quality issues you face today often trace back to schema drift.
But tomorrow's issues will stem from semantic drift: business meanings that evolve without structural changes. As your customer segments shift or product hierarchies evolve, your agentic systems will need to catch inconsistencies in meaning, not just format.

For you, semantic memory, vector understanding, and context-aware validation are becoming essential for maintaining trustworthy, AI-ready data.
As agentic operating models mature, your data engineers will shift from hand-coding transformations to supervising autonomous systems. That means designing guardrails, reviewing agent decisions, and resolving novel edge cases as they arise.
This shift makes explainability core to your model. Reasoning traces, auditable logs, and human-in-the-loop checkpoints become required for trust and compliance. You are no longer just building pipelines; you are governing intelligence.
Warm regards,
Shen and Team