The 1,000 DAG Problem: Why Airflow Breaks at Scale
When Good DAGs Go Bad...
Shen Pandi
March 09, 2026
You’ve been staring at the red “failed” task for an hour. The logs show nothing useful, just a generic error that vanishes when you retry manually. Your code works perfectly in staging.
The transformations are solid. The data looks clean. Yet somehow, in production, your Airflow DAGs keep collapsing like a house of cards.
Here’s the uncomfortable truth: your code isn’t the problem. The real culprit is sitting in your assumptions about how production actually behaves.
When you develop locally, everything runs in a pristine bubble. Your database connections are fast. Your API responses arrive in milliseconds. Your worker has unlimited memory. But production operates under completely different physics.
Your tasks aren’t failing because the Python is wrong, they’re failing because you assumed the world would cooperate. Consider what actually happens at 2:00 AM when your DAG runs:

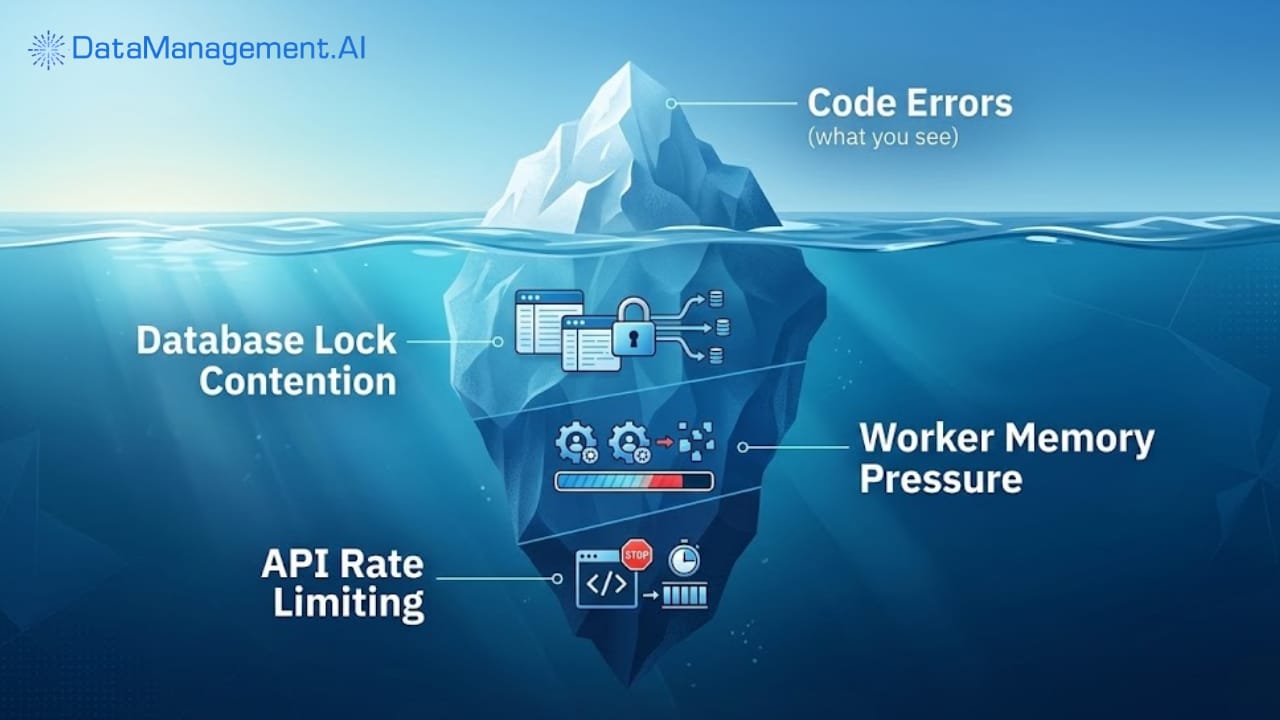
Your database is under heavy load from another team’s maintenance window. The API you’re calling is rate-limiting because a dozen other pipelines woke up at the same time. Your worker node is struggling with memory pressure because someone deployed a memory-hungry task to the same queue.
These aren’t code failures. They’re environmental failures. And Airflow gives you the tools to handle them, if you stop treating them as exceptions and start treating them as inevitable.
The Dependency Delusion
Take a hard look at your DAG dependencies. You probably defined them perfectly: Task A feeds into Task B, which triggers Task C. Clean, linear, predictable. But in production, dependencies aren’t just about task order; they’re about data availability, system capacity, and external state.
That task that downloads a file from an FTP server? It fails because the server was temporarily unreachable. But instead of building retry logic with exponential backoff, you let it fail hard and wake you up at 3:00 AM.
That transformation task that processes 100MB of data locally? It worked fine until someone upstream started sending 2GB files. Your code didn’t change. Your assumptions about data volume did.
You’re treating external systems as reliable when they’re fundamentally unreliable. Every API, every database, every file transfer is a potential failure point. Your code isn’t the weak link; your expectations are.
The Visibility Trap
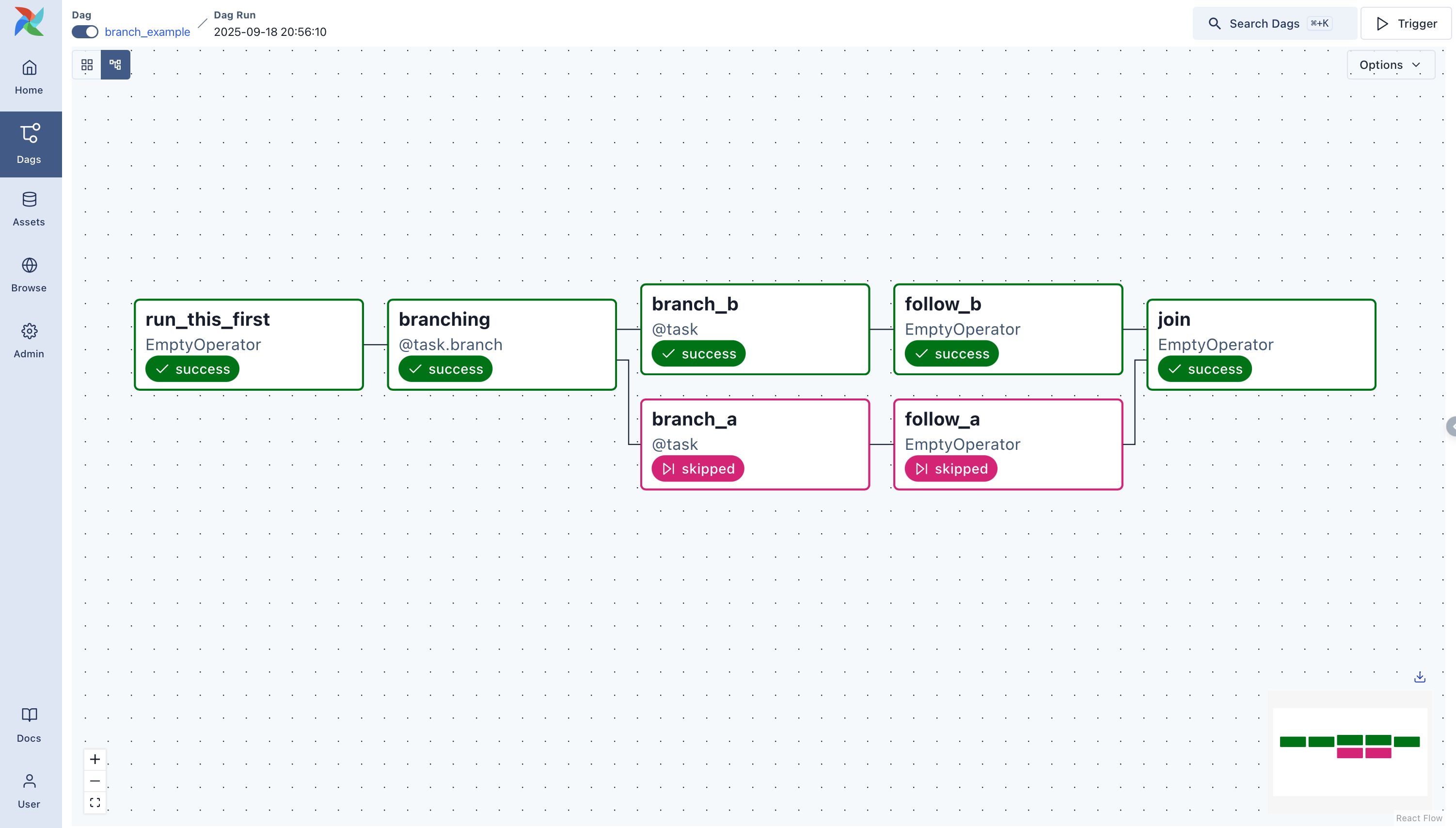
Here’s another uncomfortable realization: you don’t actually know what’s happening in your pipelines. You look at the Airflow UI, see a failed task, and assume you understand why. But the UI shows you symptoms, not causes.
When a task times out after six hours, is it because the data volume exploded? Because a database lock was held too long? Because your worker ran out of memory and started swapping? The logs won’t tell you. They’ll just show the last successful line of code before everything froze.
from airflow.decorators import task
@task
def collect_data():
print("Collecting event data...")
return "raw_events.csv"
@task
def transform_data(file):
print(f"Transforming {file}")
return "clean_data.csv"
@task
def upload_to_s3(file):
print(f"Uploading {file} to S3...")
*# Link tasks by calling them in sequence*
upload_to_s3(transform_data(collect_data()))You need observability beyond Airflow. You need to know what your database was doing during that failure window.
What your workers’ CPU and memory looked like. Whether your network bandwidth was saturated by another job. Without this context, you’re debugging blind, attributing failures to code when the real issues are systemic.
The Scaling Assumption
Remember when you tested your DAG with three files, and it finished in two minutes? Now it’s processing three thousand files and taking three hours. Your code didn’t change. Your processing logic didn’t change. But your assumptions about linear scaling just hit reality.
@task
def get_files():
return ["file1.csv", "file2.csv", "file3.csv"]
@task
def transform_file(file):
print(f"Transforming {file}")
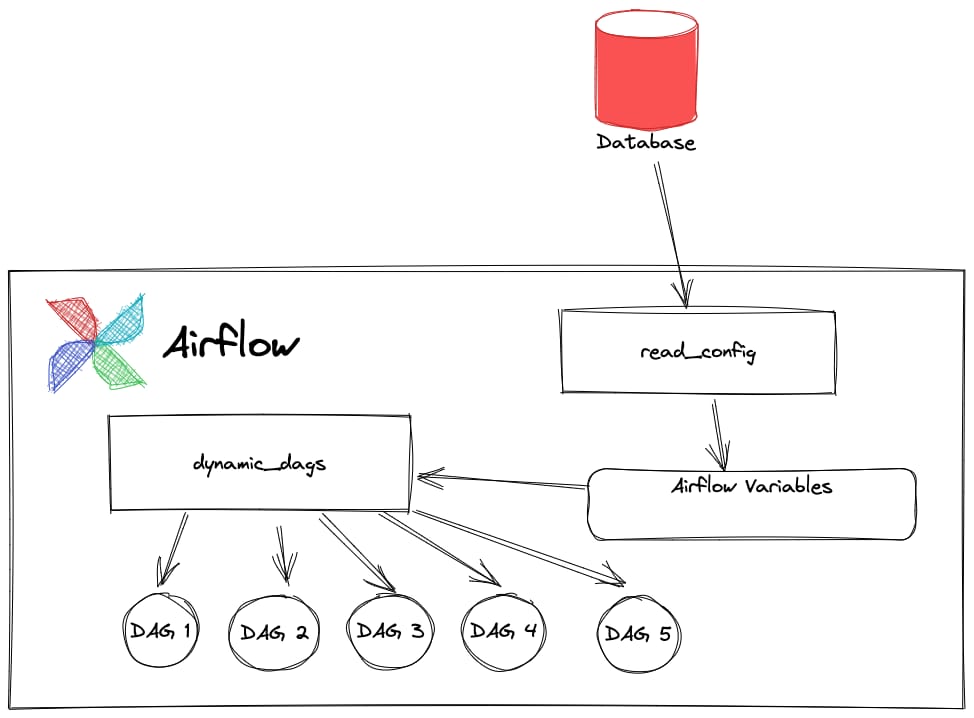
transform_file.expand(file=get_files())Dynamic task mapping is powerful, but it reveals the cracks in your infrastructure. When you expand a task across a thousand files, you’re not just scaling your code; you’re scaling your database connections, your API calls, your file handles.
If you haven’t designed for this concurrency, your tasks will fail in spectacularly non-obvious ways.
The Scheduling Myth
You set your DAG to run at 2:00 AM because that’s when nothing else happens. Except everything else also runs at 2:00 AM. Your data warehouse is flooded with ETL jobs. Your message queues are backing up. Your API endpoints are drowning in requests.

Your task fails not because of what it does, but because of when it does it. The code is identical to the version that runs perfectly at noon. The environment just can’t handle the load.
Building for Reality
So what do you actually do about this? Stop treating Airflow as a code execution engine and start treating it as a distributed systems coordinator.
Design every task to fail. Build idempotency into everything so retries are safe. Set meaningful timeouts based on real production data, not local tests. Monitor your infrastructure, not just your task statuses. Understand that your code is only one small part of a complex system.
The next time your DAG fails, don’t ask “what’s wrong with my code?” Ask “What assumption about my production environment just broke?” The answer will almost always surprise you, and it’s never the code.
Warm regards,
Shen and Team