One API Change Can Rewrite Your Entire Data Model
and your pipelines are too quiet to tell you
Shen Pandi
March 30, 2026
If your data models suddenly start producing inconsistent outputs, the issue is often not in your transformation logic or warehouse queries. It usually begins much earlier, in an upstream API that changed without warning.
In development, API responses are stable, predictable, and often mocked or sampled. But in production, APIs evolve continuously as fields are added, renamed, deprecated, or returned with different structures depending on edge cases.
These changes rarely break the pipeline outright. Instead, they alter the shape and meaning of incoming data just enough to distort downstream models.
Now, the same pipeline continues to run, the exact models continue to train, and the old dashboards continue to update. But the assumptions your data models were built on no longer hold.
Over time, the joins become less reliable, feature distributions shift, and metrics begin to drift in ways that are difficult to trace back to a single cause.
How Stripe Faced API-Induced Data Drift
Stripe’s payment infrastructure relies heavily on API-driven event streams, where transaction data flows across multiple services for processing, reconciliation, and financial reporting.
In this setup, even small changes in API responses can have cascading effects across downstream systems.
One complex challenge Stripe has dealt with involves changes in how fee and balance transaction data are returned across API versions.
Fields like application fees, refunds, or currency conversions can appear differently depending on the API version, payment method, or region. In some cases, fields that were previously embedded within a response were moved to nested objects or required additional API calls to retrieve complete details.
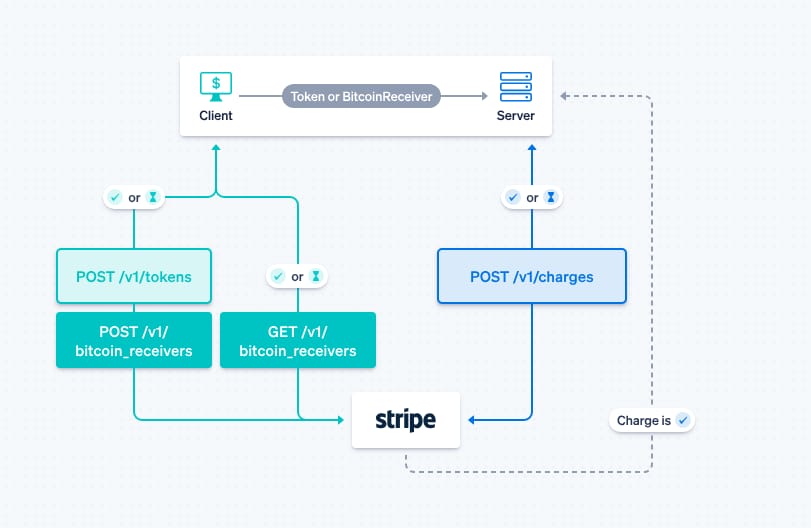
Source: Stripe
In development environments, these differences are often missed because test data is limited and API responses are consistent.
However, in production, these variations lead to incomplete or mismatched data being ingested into pipelines. Revenue models that depend on fee breakdowns or net transaction values can start producing inconsistent results when certain fields are missing, delayed, or structured differently.
The pipelines continue to run without errors, but financial aggregations and reconciliations begin to drift across systems.

To handle this, Stripe introduced stricter API versioning controls, enforced schema validation, and built internal tooling to monitor changes in API responses across services.
By making API behavior more predictable and ensuring consumers validate incoming data against expected structures, they reduced discrepancies and improved consistency between operational data and financial reporting.
The Area Where Most Pipelines Fall Apart
The real issue is that most pipelines treat API data as inherently trustworthy. Once the data is ingested, it is assumed to be structurally and semantically consistent with previous versions. There are rarely checks to validate whether the distribution, completeness, or meaning of that data has changed over time.
This is where DataManagement.AI’s Operational Anomaly Detection becomes critical. By continuously monitoring time-series metrics such as transaction volumes, null rates, and field-level distributions, it establishes a baseline of expected behavior and flags deviations as they occur.
If an upstream API starts returning incomplete data or changes the structure of key fields, those shifts show up immediately as anomalies rather than being discovered days later during reconciliation.

Because it also incorporates contextual signals like system load, recent deployments, and incident logs, the system can correlate anomalies directly with upstream changes.
Instead of debugging blindly, teams can quickly identify whether a spike or drop in metrics is tied to an API change, reducing both detection time and resolution effort.
The One Gap That Makes API Changes So Dangerous
The fundamental gap is not just the absence of monitoring, but the lack of explicit contracts between APIs and data models. Most data pipelines are built on implicit assumptions about API responses, such as field availability, data types, and nested structures.
When APIs evolve, those assumptions break, but nothing enforces alignment between producers and consumers.
Unlike internal schemas, external APIs often change without strict versioning or backward compatibility guarantees. This means your data models are effectively coupled to systems you do not control.
Without validation layers that check incoming data against expected structures and distributions, these changes propagate silently.
How DataManagement.AI solves the issue
Closing this gap requires treating APIs as dynamic inputs rather than fixed sources. Schema validation, anomaly detection, and continuous monitoring need to be embedded into the ingestion layer itself.
When that happens, API changes stop being silent disruptors and become observable events that can be managed before they impact your models.
Warm regards,
Shen and Team