How to Catch Schema Changes Before They Break Production
why everything runs but nothing matches
Shen Pandi
April 07, 2026
Most teams rely on pipeline success as a proxy for data correctness, but execution success only confirms that the system ran, not that it produced valid outputs. Schema changes rarely trigger failures because modern pipelines are built to be fault-tolerant. They coerce types, ignore unknown fields, and continue processing even when the underlying structure shifts.
This creates a blind spot. When a field transitions from required to optional, null propagation begins affecting joins and aggregations. When new enum values are introduced, downstream filters and case logic fail to account for them, leading to silent misclassification. When nested schemas evolve, deserialization logic may still execute, but extract different fields than intended.
These changes do not interrupt the pipeline. They alter its behavior.
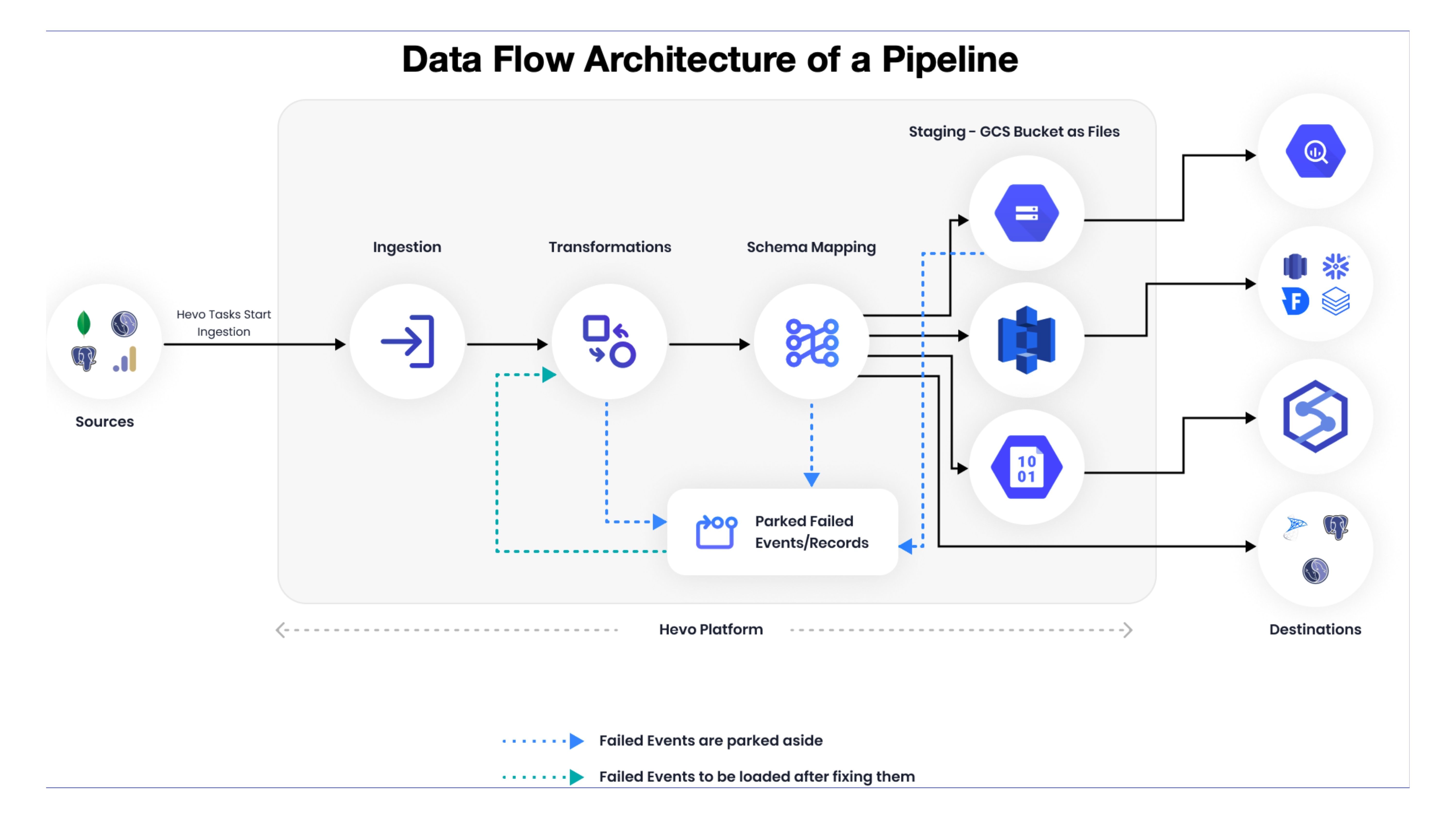
By the time discrepancies surface in dashboards or models, the change has already propagated through multiple transformations and storage layers. At that point, you are no longer detecting a schema change. You are debugging its downstream consequences.
Why Are Your Current Checks Useless Against Real Schema Changes?
Most validation layers stop at schema enforcement, which means they verify structure but ignore execution semantics. A field exists, the data type matches, and the pipeline proceeds, but none of these checks validate how that field behaves once it flows through transformations, joins, and aggregations.
Take enum expansion as an example. When an upstream service introduces new values, the schema remains valid because the column type has not changed. However, downstream logic often encodes assumptions about allowed categories. Case statements, filters, and aggregations begin to either drop or misclassify these new values, creating silent distortions in metrics.
A similar issue occurs when a non-nullable field becomes optional. Schema validation passes, but null propagation alters join cardinality, impacts group-by completeness, and changes the distribution of derived features. These shifts do not trigger failures, but they systematically degrade data correctness.
The gap is not at ingestion, it is in validating how data behaves under transformation. Without checks on cardinality, distribution, and logical consistency, schema validation becomes a superficial safeguard.
How to Actually Catch Schema Changes?
Catching schema changes early isn’t just about running a nightly validation script. True protection requires continuous observability across your data stack. You need to know not just that a schema changed, but how that change propagates through every transformation, join, and aggregation in real time.
It starts with enforcing schema contracts and compatibility checks at ingestion. Any modification to structure, field presence, or allowed values should be validated against expected definitions before it’s allowed to flow downstream. Missing this layer is what turns minor upstream tweaks into cascading errors across dashboards and reports.
But structure alone isn’t enough. You need visibility into how fields flow across systems, which is where DataManagement.AI fit naturally. Its Data Lineage & Governance capabilities trace every column from origin to consumption, pulling metadata from ETL jobs, version histories, and access logs. When a schema evolves upstream, you can instantly see which pipelines, transformations, and dashboards will be affected, enabling proactive risk assessment before deployment.
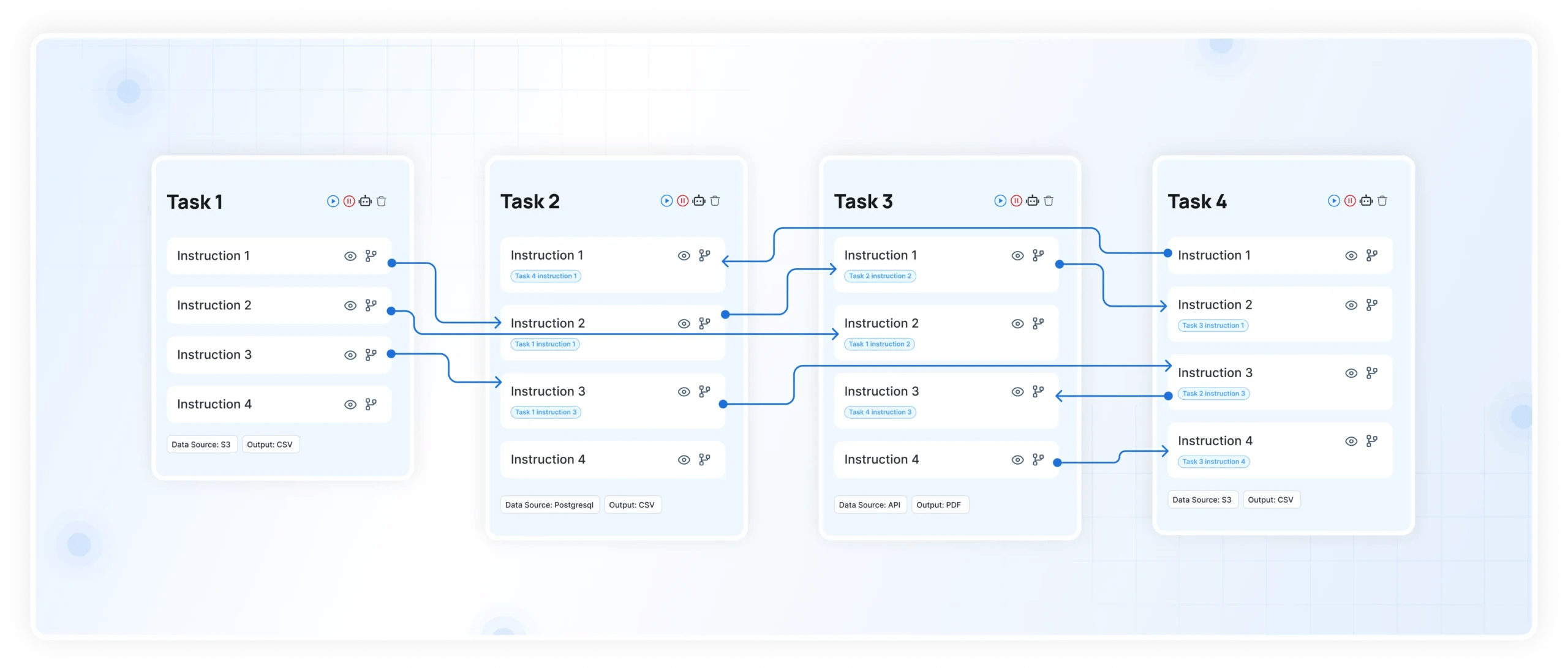
Meanwhile, Data Quality Monitoring continuously measures the health of your datasets, validating schema definitions, nulls, ranges, and referential integrity across time. Historical error trends, pass rates, and pinpointed rule violations surface deviations early, so subtle anomalies like a column shift affecting aggregation are caught immediately instead of days later during reconciliation.
Finally, pairing lineage visibility with anomaly detection ensures that semantic changes don’t slip through unnoticed. If joins suddenly produce fewer records, distributions drift, or derived metrics shift outside expected ranges, the system flags it in real time. By integrating these features directly into pipelines, teams gain confidence that schema evolution won’t silently break production.

The goal isn’t to prevent schema changes, they’re a normal part of growth but to make their impact observable and manageable. With the right tooling, what used to be silent, costly failures become predictable events, and production dashboards stay trustworthy no matter how rapidly upstream systems evolve.
The One Thing Most Teams Still Refuse to Do
Most teams know what needs to be done. They just do not implement it fully.
Schema contracts are often treated as documentation rather than enforceable rules. Staging environments are assumed to reflect production, even though real data behaves differently. Monitoring focuses on pipeline execution instead of data correctness.
The gap is not knowledge. It is discipline.
If you want to catch schema changes before they break production, you need to treat schemas as contracts, enforce compatibility at every stage, and continuously validate how data behaves across systems.
Otherwise, you are not managing schema changes. You are waiting for them to show up in your most critical dashboards.
Warm regards,
Shen Pandi & Team