How One Column Rename Can Take Down Your Entire Data Stack
when a “small change” isn’t small
Shen Pandi
March 26, 2026
Renaming a column usually feels harmless. Teams do it to improve clarity, standardize naming conventions, or align datasets across systems.
The problem is that in production, that column is rarely just a field sitting in isolation. Over time, it becomes deeply embedded across dashboards, ETL pipelines, feature stores, and reporting layers, often owned by different teams who may not even be aware of each other’s dependencies.
Some of these connections are documented, but many exist quietly in legacy queries, scheduled jobs, or downstream tools that no one actively monitors.

Because of this, the impact of a rename is almost never immediate or obvious. Pipelines don’t necessarily fail, dashboards don’t stop loading, and metrics can still appear stable at a glance.
What actually happens is more subtle joins start returning incomplete results, aggregations lose accuracy, and downstream systems begin working with data that is technically valid but contextually wrong.
And, by the time someone notices, the issue has already spread across multiple layers of the data stack.
The Chain Reaction Across Your Data Stack
When a column is renamed, every downstream system that depends on it reacts differently. Some pipelines fail fast if strict schema validation is in place. Others, especially those using loosely typed transformations or backward-compatible logic, continue running but produce incorrect outputs.
A join that previously matched on ‘user_id’ may now return partial results if one dataset expects ‘user_id’ and another receives ‘customer_id.’ Aggregations that rely on that join begin undercounting records. Feature pipelines feeding machine learning models start training on incomplete data.
This is where silent failure becomes dangerous. Without continuous validation, there is no immediate signal that something has broken.
This is exactly the gap DataManagement.AI addresses through its monitoring capabilities, where schema changes are tracked against expected structures and anomalies in downstream metrics are detected in real time.
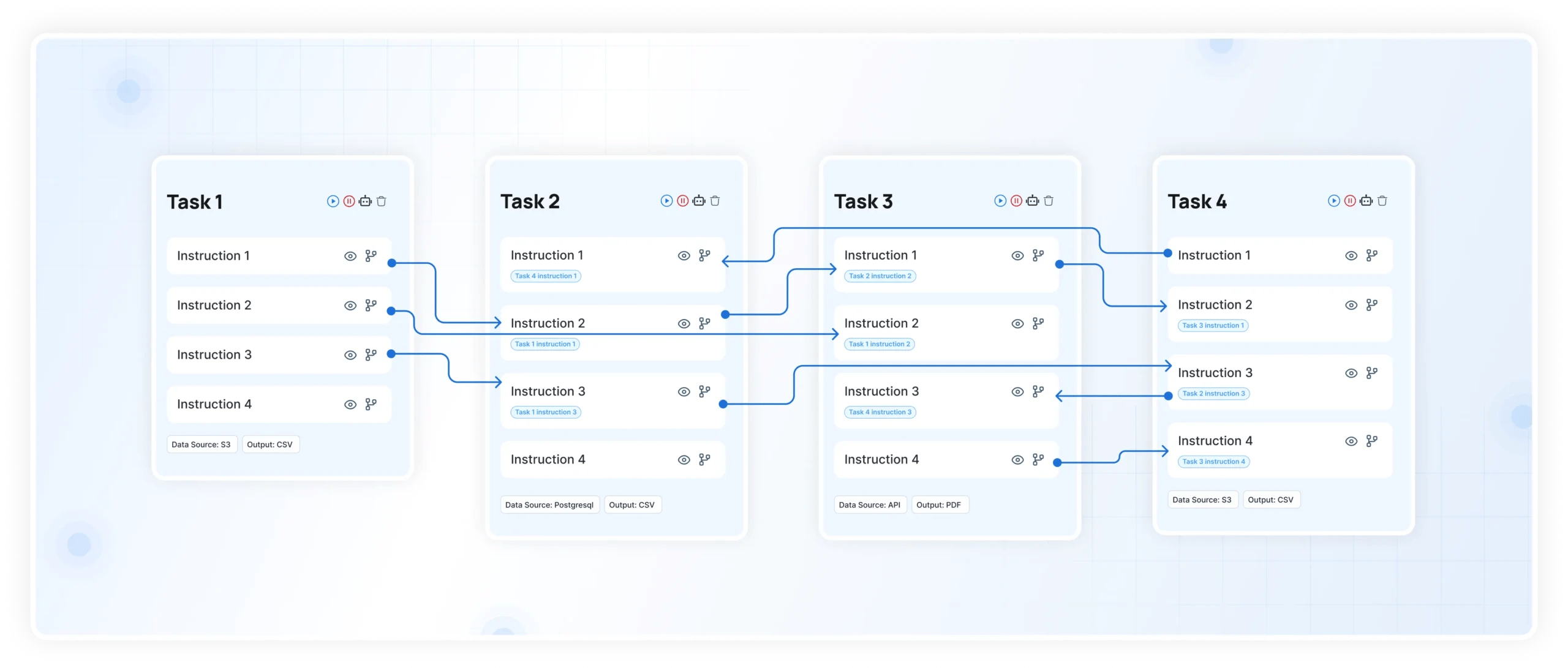
By analyzing time-series patterns across critical metrics and comparing them to historical baselines, even subtle drops in join success rates or unexpected shifts in data distributions can be flagged early, before they propagate into business decisions.
Why Do Most Teams Don’t Catch It in Time?
The real issue is not just visibility, it is how modern data systems handle schema changes under the hood.
Many pipelines are designed to be fault-tolerant, which means they easily handle missing or renamed fields instead of failing. Serialization frameworks like Avro or Parquet, along with loosely enforced schemas in data lakes, often allow backward compatibility by ignoring unknown fields or defaulting missing ones to null.
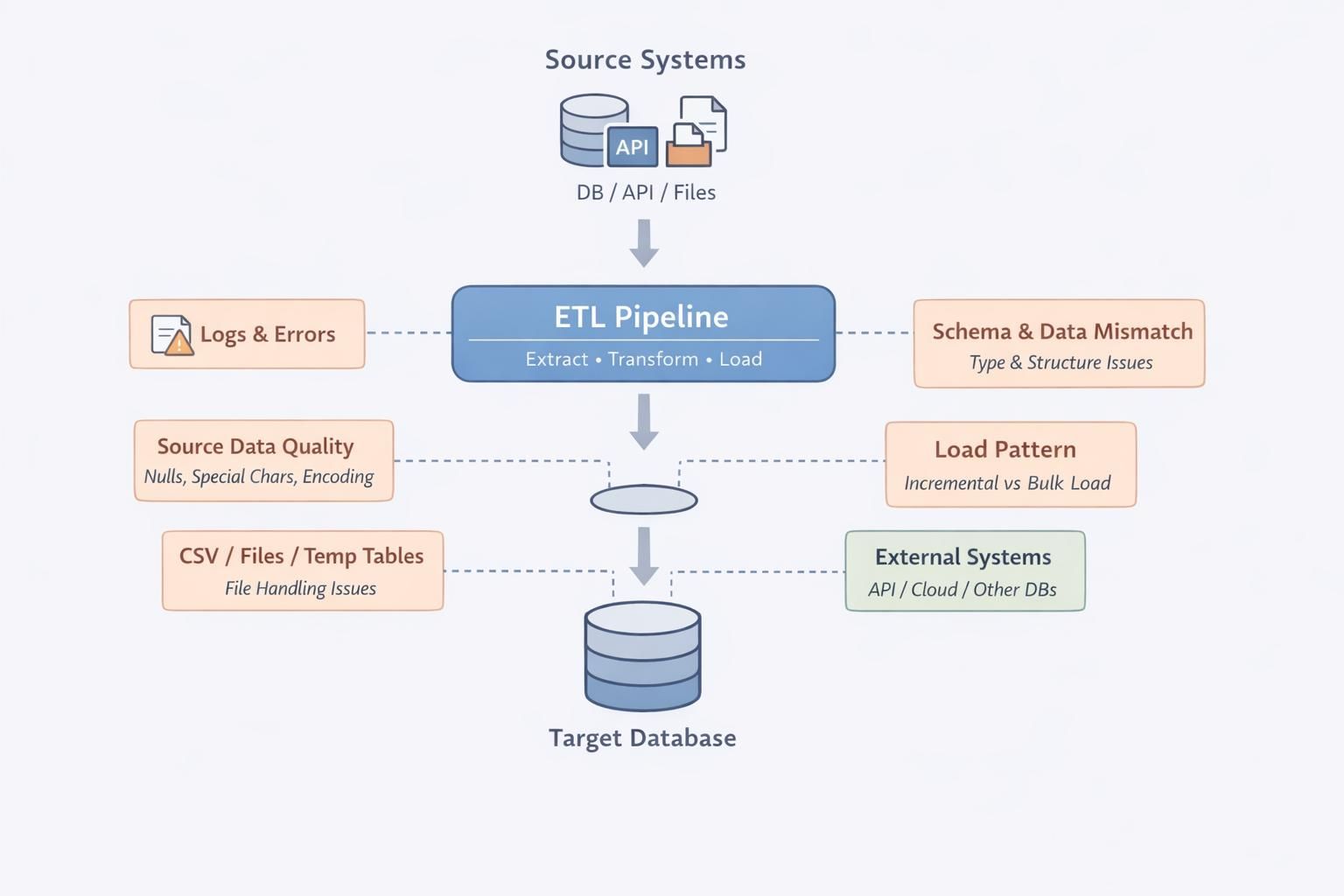
This behavior keeps pipelines running, but it also masks problems. A renamed column may quietly get dropped during deserialization, or worse, get replaced with null values that flow through aggregations and joins without triggering errors.
Downstream systems then compute metrics on incomplete datasets, and because the structure still “fits,” nothing raises a red flag.
This is where DataManagement.AI’s Operational Anomaly Detection becomes critical. By tracking time-series patterns in metrics like join success rates, null distributions, and aggregation outputs, it identifies subtle deviations from historical baselines.
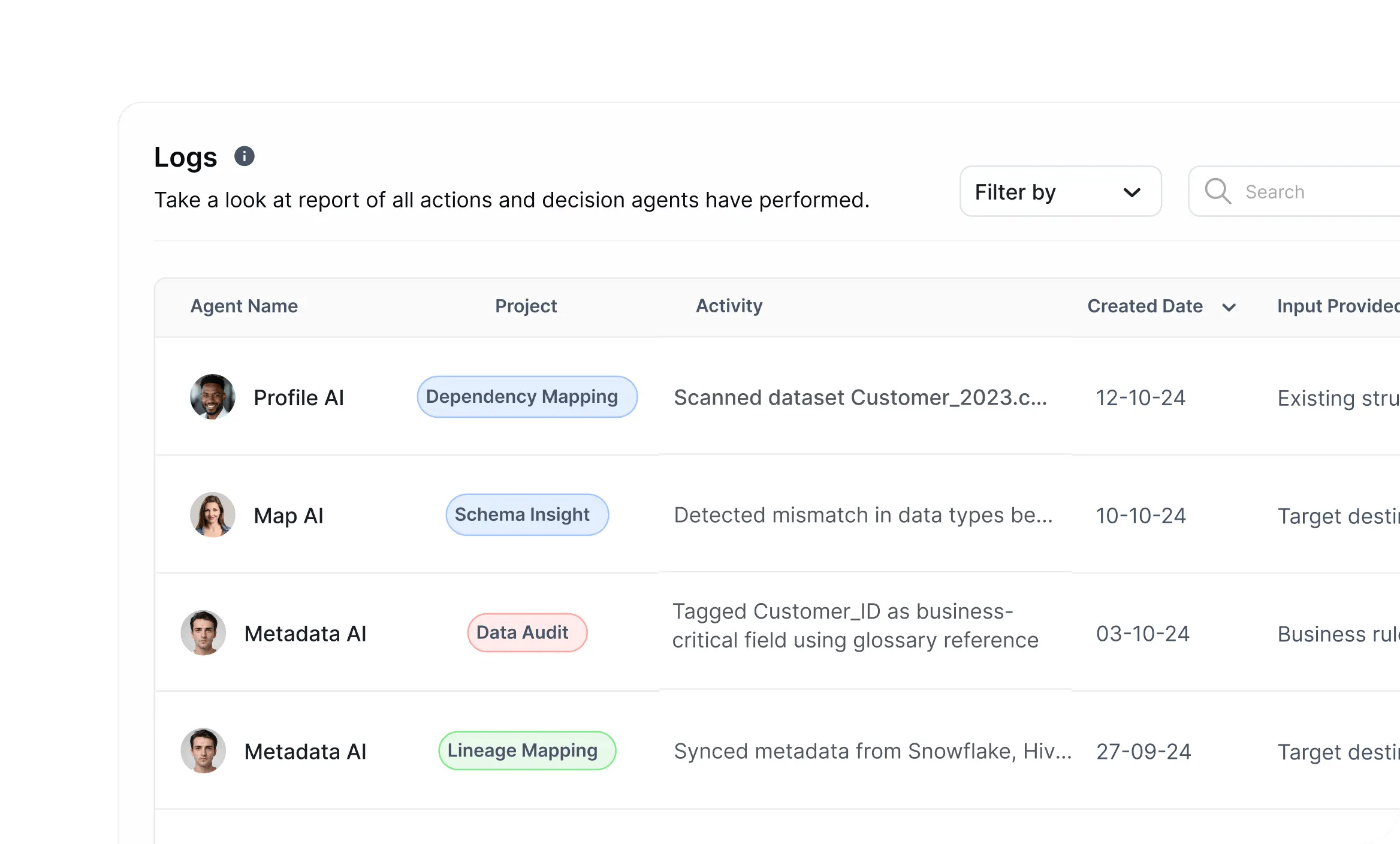
When combined with contextual signals such as recent schema changes or deployments, it helps teams pinpoint exactly when and where the breakdown began, turning silent failures into visible, actionable insights.
The One Gap That Causes the Entire Failure
The issue usually comes down to how tightly your transformations are coupled to schema assumptions at execution time.
Most pipelines are written with implicit expectations about column names, data types, and nullability, but those expectations are rarely enforced anywhere. When a column is renamed, the logic does not always break, it adapts in unintended ways.
For example, in SQL-based transformations, a missing column in a join condition might not throw an error if fallback logic or coalescing is used.
Instead, the join cardinality changes. You might move from a one-to-one join to a one-to-many or even a many-to-many relationship without realizing it.
That leads to duplicated rows, inflated aggregates, or dropped records depending on how the query is structured.
In distributed systems like Spark or streaming pipelines, this gets even more complex. Schema inference, column pruning, and lazy evaluation can delay when the impact becomes visible, so jobs succeed while silently producing incorrect outputs.
Without column-level lineage, join validation, and runtime checks on cardinality and distributions, these shifts go undetected. The pipeline still runs, but the meaning of the data has already changed.
Warm regards,
Shen and Team