5 Data Engineering Trends for 2026 That Giants Don't Want You to Know
Is Your Stack Ready for 2026?
Shen Pandi
December 24, 2025

Trend 1: Centralize tool sprawl into a managed internal platform.
Trend 2: Adopt event-driven flows as the new architectural default.
Trend 3: Operationalize AI for proactive system intelligence.
Trend 4: Enforce trust automatically with data contracts.
Trend 5: Engineer for cost efficiency as a first-class requirement.
The 100 Most Influential Leaders in Generative AI

Data engineering is currently navigating its most significant transformation in a decade. While the foundational challenges of scale, reliability, and cost remain, you now face a more complex operating environment defined by tool sprawl, cloud fatigue, and an uncompromising demand for real-time insights.
This is no longer just a technical role; it's a strategic one. Your success now hinges not on adopting the latest ephemeral framework but on evolving your architectural philosophy, operational discipline, and organizational influence.
As you look toward 2026, the future of your profession is being shaped by structural shifts in how data ecosystems are built and governed.
The conversation has moved past "which tool?" to deeper questions: Who owns the infrastructure? How do we guarantee trust in real-time? How do we operate sustainably at scale?
The leaders in this new era will be those who master clarity, intentionality, and a product-centric mindset.
This guide outlines the five pivotal trends that will define your journey, providing a strategic blueprint to navigate this evolution from a builder of pipelines to an architect of intelligent, reliable, and business-critical platforms.
Trend 1: The Rise of Platform-Owned Data Infrastructure, Your Shift from Toolsmith to Platform Collaborator
For the better part of a decade, your reality has likely been an expanding sprawl of best-of-breed tools. You integrated a new streaming processor here, a specialized transformation engine there, each chosen to solve a specific, immediate problem.
In practice, this created a fragile patchwork of systems, a "Frankenstack", where ownership was diffuse, and accountability was blurred. A dashboard breaks: is it the data quality?
The transformation logic? Is the ingestion job owned by another team? You spend more time playing detective than engineering.
The emerging and definitive trend is a decisive move away from this fragmentation toward centralized, platform-owned infrastructure. This means the creation of dedicated internal platform teams whose sole product is the data development environment.
Your relationship with your stack is fundamentally changing: you are transitioning from a toolsmith who assembles and maintains a personal toolkit to a platform collaborator who leverages a robust, standardized internal product.
In this new model, a central platform team provides you with hardened, opinionated building blocks: a unified ingestion framework, a curated library of transformation templates, standardized deployment patterns, and a centralized observability suite.

These are not suggestions but the paved path. Your creativity and expertise are channeled upward, away from the plumbing, toward what truly matters: data modeling, semantic definition, and delivering business logic with high quality.
This is not about limiting your freedom but about elevating your impact. The platform team shoulders the burden of operational excellence, defining clear service-level objectives (SLOs), managing failure modes, and orchestrating seamless upgrades.
This allows you to focus on delivering data products, not babysitting infrastructure. The most profound change is the product mindset.
Your internal platform is treated with the same rigor as an external SaaS product; it has a roadmap, user feedback loops, and a commitment to reliability. This disciplined ownership is non-negotiable as data pipelines become the central nervous system of the modern enterprise.
For you, this means your role evolves from a cost center maintaining brittle scripts to a value center collaborating on a strategic platform.

Trend 2: Event-Driven Architectures as the Default, Your New Paradigm of Continuous Data Flows
Batch processing will always have its place for large-scale historical analysis, but its reign as the default architectural pattern is over. The gravitational center of data engineering is shifting decisively toward event-driven architectures.
The business mandate is clear: freshness, responsiveness, and real-time contextual awareness are now competitive imperatives.
Whether it's detecting fraud within milliseconds, personalizing a user experience in-session, or monitoring supply chain disruptions, the value of data decays rapidly with latency.
The great news for you is that the operational barrier to entry has collapsed. Managed streaming services, robust message brokers (like Apache Kafka and its cloud-managed siblings), and mature stream-processing frameworks (like Apache Flink) have commoditized the once-daunting complexity of real-time systems.

In 2026, building an event-driven pipeline should be as straightforward, if not more so, than building a cron-scheduled batch job.
Your success here requires a fundamental shift in perspective. You must stop thinking in terms of discrete "jobs" and start thinking in terms of continuous "data flows." This new paradigm brings specific, non-negotiable design principles that you must embed into your practice:
1) Schema-First, Validate-at-Ingestion: In a batch world, you could load raw data and clean it later. In an event-driven world, this creates a toxic data swamp. You must enforce strong schema discipline at the point of production.
Every event must be validated against a predefined contract before it enters your stream. This prevents garbage data from poisoning dozens of downstream consumers and forces upstream teams to be responsible producers.
2) Decouple Transport from Processing: A resilient architecture cleanly separates the concerns of message delivery from message processing. Use your message broker for what it's best at: durability, ordering, and guaranteed delivery.
Use your stream-processing framework for stateful transformations, aggregations, and enrichment. This separation reduces systemic coupling and makes each layer independently scalable and manageable.
3) Design for Deterministic Replay: Your pipelines must be built with the assumption that you will need to replay history.
Whether for debugging a logic error, recovering from a corruption, or backfilling a new derived dataset, the ability to replay a stream of events from a past point in time and get the exact same output is a superpower. This requires careful design around idempotency and state management.
Mastering this flow-centric mindset means elevating concepts like schema evolution, backpressure handling, and end-to-end latency from afterthoughts to first-class design criteria.
By 2026, proficiency in event-driven design will be a core competency, not a niche specialization, positioning you to build the responsive, intelligent systems your business demands.
Trend 3: AI-Assisted Engineering Becomes Operational, Your Intelligent Co-Pilot for Scale
AI has already touched your world through code autocompletion and chatbot-style Q&A. This is just the prelude.
By 2026, AI will evolve from a development aid to an embedded, operational co-pilot, fundamentally changing how you monitor, debug, and optimize your data estate.
The catalyst is the vast, untapped ocean of operational metadata your systems already generate: query execution plans, detailed pipeline logs, full data lineage graphs, and granular resource utilization metrics.
Today, you query this data reactively, when a pipeline fails or a dashboard times out. AI transforms this exhaust into a proactive intelligence layer. Imagine a system that:
Predicts performance degradation by analyzing subtle shifts in query patterns days before a critical pipeline misses its SLA.
Automatically surfaces root causes by correlating a data quality alert in a dashboard with a specific schema change deployed 72 hours earlier, complete with a suggested rollback script.
Recommends optimizations like optimal partitioning keys, materialized views, or cluster resizing based on actual usage patterns, not guesswork.
Detects semantic drift by identifying that the statistical distribution of a key column has shifted, potentially indicating a broken source application or a new business process.
For you, the impact is transformative. You will spend less time in reactive "firefighting" mode, manually sifting through logs across five different tools.
Instead, you will spend your time on higher-order tasks: making informed architectural decisions, refining data models, and collaborating with business stakeholders.
This AI co-pilot doesn't replace your deep domain expertise; it amplifies it. It handles the scale and pattern recognition at which machines excel, freeing you to focus on the judgment, context, and design at which humans excel.
In an era of "do more with less," this operational intelligence is not a luxury; it's your force multiplier for maintaining reliability and velocity.
Trend 4: Data Contracts and Shift-Left Governance, Your Blueprint for Built-in Trust
The era of discovering data quality issues in a broken executive dashboard is ending. It is too late, too expensive, and destroys trust. The proactive response, rapidly moving from theory to standard practice, is the enforceable data contract.
A data contract is a formal agreement between a data producer (e.g., an application team) and its consumers (e.g., your analytics team). It codifies explicit promises: the schema (structure), freshness (latency), volume (throughput), and semantic meaning of a dataset.
Your role is to make these contracts machinery, not paperwork. In 2026, successful teams will integrate contract validation directly into their CI/CD and data ingestion workflows.
When a producer application commits code that changes an API output schema, a contract test runs automatically.
If the new output violates the agreed-upon contract, the build fails. The break is caught at the source, minutes after the change is made, not days later when downstream models fail. This is "shift-left" for data quality.
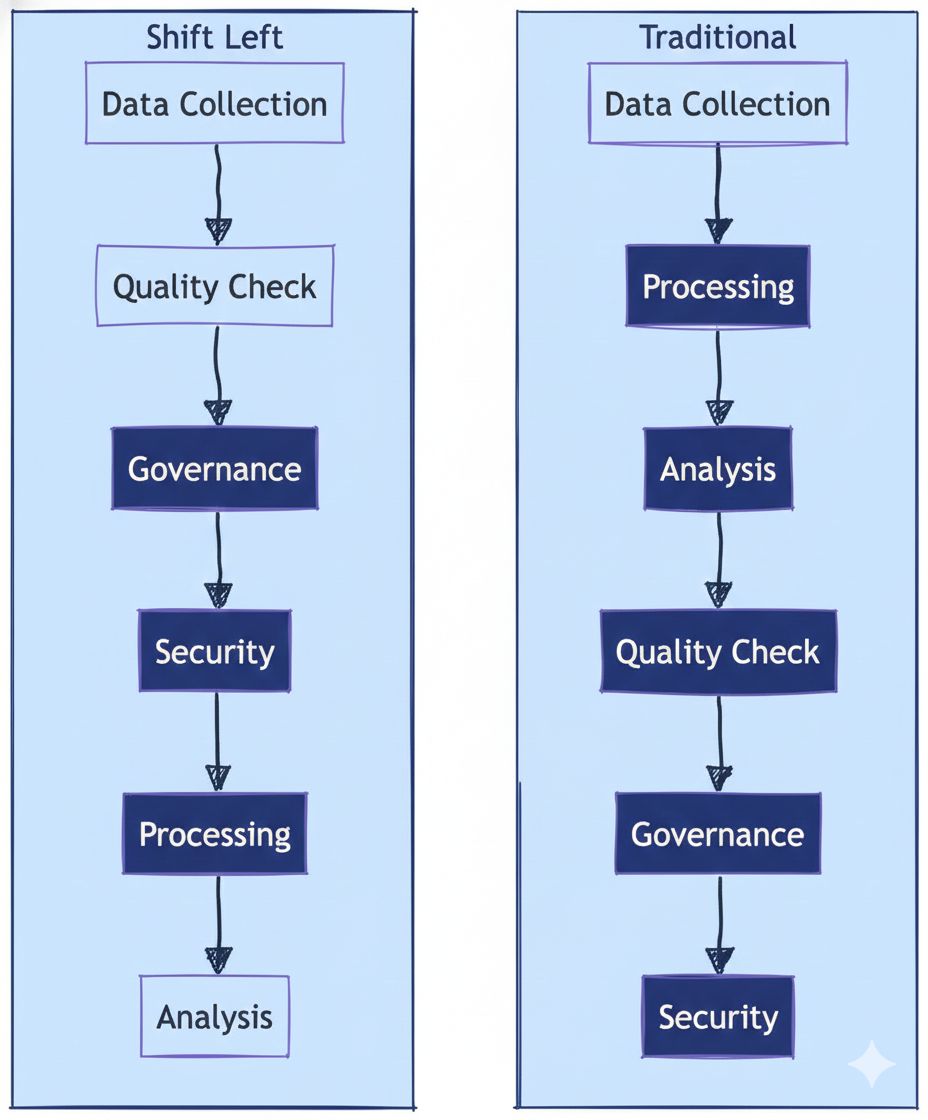
This philosophy extends to governance. Instead of a security team conducting a retrospective audit of your data lake, access controls, privacy policies (like PII masking), and compliance requirements (like GDPR right-to-delete) are defined declaratively and enforced automatically within the pipeline itself.
Data lineage is not a separately generated report but an inherent property of the system, tracked from source to consumption.

For you, this trend means moving from being a gatekeeper who manually checks data to an enabler who builds systems that are trustworthy by design. It reduces friction with legal and security teams because controls are baked in.
It creates clear accountability: the contract defines the promise, and the automated enforcement holds producers to it. The result is a data ecosystem where consumers can trust what's in the pipeline, allowing you to deliver insights with confidence.
Trend 5: The Return of Cost-Aware Engineering, Your Mandate for Sustainable Scale
The "cloud-first, ask questions later" era has given way to a necessary and profound focus on financial discipline. Data engineering workloads are consistently among the largest line items in a company's cloud bill.
In 2026, you will be expected to wield cost as a primary design lever, alongside performance and reliability.
This is not about frugality for its own sake; it is about sustainable scale, ensuring your data platform can grow with the business without becoming a financial albatross.
This translates into a new set of core competencies for you:
Intentional Storage Management: You will strategically leverage storage tiers (hot, warm, cold, archival) based on access patterns, not just default to the most expensive option. You will implement lifecycle policies automatically.
Precise Compute Right-Sizing: The days of over-provisioning "to be safe" are over. You will use monitoring tools to profile workloads and match compute resources (CPU, memory, GPU) precisely to need. You will schedule non-critical jobs to run on spot instances or during off-peak hours.
Query and Transformation Efficiency: You will actively analyze and optimize expensive queries, eliminate redundant data movements, and prune unused datasets. Cost will be a key metric in your performance tuning efforts.
Architectural Cost Analysis: When evaluating a new tool or design pattern, you will model its total cost of ownership (TCO). The question "How will this scale?" will be accompanied by "At what monthly cost?"
Critically, you will have the tooling to make this possible. FinOps (Financial Operations) practices will be integrated into your workflow, giving you clear, granular visibility into which team, pipeline, or even query is driving spend.
This turns cost conversations from vague, top-down mandates into concrete, collaborative optimization sessions with your stakeholders. Your goal is to build a platform that is not just powerful, but also economically rational, a true asset to the business.
These five trends are not isolated; they are interconnected strands of a single, more mature future for data engineering. Platform ownership provides the foundation for event-driven flows.

AI-powered ops provide the visibility to manage them. Data contracts ensure their quality, and cost-awareness guarantees their sustainability.
Your role is expanding in scope and strategic importance. You are no longer just the expert who keeps the data flowing. You are becoming:
The platform strategist who champions internal products over fragmented tools.
The real-time architect who designs for continuous flow, not periodic batches.
The efficiency engineer who optimizes for total cost, not just technical performance.
The guardian of trust who engineers quality and governance into the fabric of the system.
The tools you use will continue to change, but the underlying values that will define success in 2026 are becoming clear: Clarity over cleverness. Ownership over operation. Intentionality over inertia. Reliability over novelty.
By embracing this cultural and technical shift, you will move your work from the background to the forefront, positioning yourself not as a supporting player but as a central architect of your organization's data-driven future. The blueprint is here. The next step is yours.
Warm regards,
Shen and Team